
Paranoia Levels are an essential concept when working with the Core Rule Set. This blog post will explain the concept behind Paranoia Levels and how you can work with them on a practical level.
Introduction to Paranoia Levels
In essence, the Paranoia Level (PL) allows you to define how aggressive the Core Rule Set is. Very often, I explain this with the help of a dog. In the default installation, you get a family dog that is really easy going. It is a breed that causes no trouble. Bring your neighbour’s kids and have them pull the dog by its tail and he won’t bite.
When you move to Paranoia Level 2, you will tell your neighbour’s kids not to go too wild with the dog because you never know. At Paranoia Level 3, you put the dog on a leash and tell the kids to leave it alone since the dog does not know them too well and you fear there might be trouble. Finally, at Paranoia Level 4, you get a dog that has to be put away when the mailman rings the bell so he does not assault him immediately as a potential attacker.
So when you buy a dog, you make a conscious decision on which breed you want to have given the situation. It is not that a Paranoia Level 4 dog is evil. It is just that it takes a lot of training and work to make sure that a Paranoia Level 4 dog does not go berserk over a false alarm, causing a kid, the mailman or a customer to be bitten as a consequence.
The same is true for the Core Rule Set and Paranoia Levels. At PL 1 you get rules that hardly ever trigger a false alarm (ideally never, but we have to admit that it can happen, depending on the local setup). At PL 2 you get additional rules that detect more attacks, but there is a chance that the additional rules will also trigger a false alarm over a perfectly legitimate HTTP request.
This continues at PL 3, where we add more rules, namely for certain specialized attacks. This leads to even more false alarms. Then at PL 4, the rules are so aggressive that they detect almost every possible attack, yet they also flag a lot of legitimate traffic as malicious.
As you can see, a higher Paranoia Level makes it harder for an attacker to go undetected. Yet this comes at the cost of more false positives: more false alarms. So there is a downside to running a rule set that detects almost everything: your business is also disrupted.
So what do you do with all the false positives? You need to tune them away. In ModSecurity-speak: you need to write rule exclusions. A rule exclusion is a rule that disables another rule, either disabled completely or disabled partially only for certain parameters or for certain URIs. That way, the rule set remains intact, yet you are no longer affected by the false positives. Depending on the complexity of your service and on the Paranoia Level, this can be a substantial amount of work.
But let’s not go deeper into the problem of handling false positives. There are various resources that explain this. The best is probably my set of tutorials where I explain this together with other techniques around working with the Core Rule Set.
Description of the 4 Paranoia Levels and How to Approach Your Management
The CRS project sees the 4 Paranoia Levels as follows:
- PL 1: Baseline Security with a minimal need to tune away false positives. This is CRS for everybody running an HTTP server on the internet. If you encounter a false positive on a PL 1 system, please report it via GitHub.
- PL 2: Rules that are adequate when real customer data is involved. Perhaps an off-the-shelf online shop. Expect false positives and learn how to tune them away.
- PL 3: Online banking level security with lots of false positives. From a project perspective, false positives are accepted here, so you need to be able to help yourself by writing rule exclusions.
- PL 4: Rules that are so strong (or paranoid) they are adequate to protect the crown jewels. Use at your own risk and be prepared to get a large number of false positives.
In light of this, you need to think about your security requirements. The difference from a personal landing page to the protection of the admin gateway that controls access to an enterprise’s Active Directory are really different. So you choose the Paranoia Level accordingly. And when you do, you also inform management that you need the adequate resources (time!) to tune away the false positives.
If a security officer walks up to you and asks you to run in PL 4, said officer also has the obligation to make sure you get many weeks worth of time to tune away the false positives. If not, you run the risk of exposing your customers to a vast number of false positives: that will lead to customer complaints, and that might ultimately mean that the Core Rule Set will be disabled by management. So setting a high PL in blocking mode without adequate tuning is very risky.
In a larger enterprise, I’ve been successful with defining guidance about how to map risk levels or the security needs of different asset classes onto Paranoia Levels. To give you a simple example:
- Risk class 0 (no customer data): PL 1
- Risk class 1 (customer names and addresses): PL 2
- Risk class 2 (online banking: highest risk class for said customer): PL 3
So there is an internal process that assesses the risk for a new (or existing) service. Once that risk is defined, it maps 1:1 to the Paranoia Level. I think it is helpful to keep it that simple!
How to Set the Paranoia Level
If you run a native Core Rule Set installation on your web application firewall then you define the PL by setting the variable tx.paranoia_level. The variable is set in crs-setup.conf in rule 900000, but technically you can also set it in the Apache or NGINX configuration (a technique that I personally use, so I always see its value).
If you are running on a CRS that has been integrated into a commercial product or Content Delivery Network, the support varies. Some vendors expose the PL setting in the graphical user interface, other vendors force you to write a custom rule that sets the tx.paranoia_level variable. Unfortunately, there are also vendors that do not allow you to set the PL at all. We consider this to be an incomplete Core Rule Set integration, since we see Paranoia Levels as a defining feature of the Core Rule Set.
Paranoia Levels and Anomaly Scoring
A frequent question I get is about the connection between Paranoia Level and the CRS Anomaly Scoring, or rather the CRS Anomaly Threshold (Limit). The answer is simple: these are two entirely different things which have no direct connection. Paranoia Levels control the number of rules that you enable and the Anomaly Threshold defines how many rules can trigger before you block a request.
At the conceptual level, you can start to mix them if you want to have a particularly granular security concept. You could say “we define the Anomaly Threshold to be 10, but we compensate for this by running Paranoia Level 3, which brings more rule alerts and higher Anomaly Scores.”
I think this is technically correct (and I have seen installations following such a concept), yet it overlooks the fact that there are attack categories where CRS scores very low. We are planning to introduce a new rule to detect POP3 and IMAP injections. This is going to be a single rule. So, in normal circumstances (and without any other rules interfering by accident), an IMAP injection can never score higher than 5. Therefore, an installation running at an anomaly threshold of 10 can never block an IMAP injection, even if running at PL 3. So my general advice is to keep things simple and separate: A CRS installation should aim for an Anomaly Threshold of 5 and a Paranoia Level as you see fit.
How to Move from One Paranoia Level to Another or Introducing the Executive Paranoia Level
Say you went for Paranoia Level 1 with your installations. There were a couple of false positives that you had to deal with, unfortunately, but now you have a clean setup with an Anomaly Threshold of 5 which blocks attackers immediately. However, you now regret that you started out with Paranoia Level 1 since you think it more appropriate to assign a Paranoia Level of 2. Now here comes the problem: with PL 2 there will be new false positives and, given your strict Anomaly Threshold, you will block legitimate customers if you do not pay attention.
The dirty way is to raise the Anomaly Threshold to a higher value for some period. Yet that is of course risky, and lowering your security posture in order to improve it is counter-intuitive and usually frowned upon.
So there is a better way. Let’s think of the Paranoia Level as the Blocking Paranoia Level. That means the rules enabled in the Blocking Paranoia Levels will be counting towards the Anomaly Threshold used to determine whether to block a request or not.
Now let’s introduce an additional Paranoia Level: the Executing Paranoia Level. This PL is equal to (this is the default) or higher than the Blocking Paranoia Level. If the Executing Paranoia Level is higher, you execute rules that might trigger false positives, but even if they do, these alerts will not count towards the Anomaly Threshold used to make the blocking decision.
Scheme with Blocking Paranoia Level at 1 and Executing Paranoia Level 2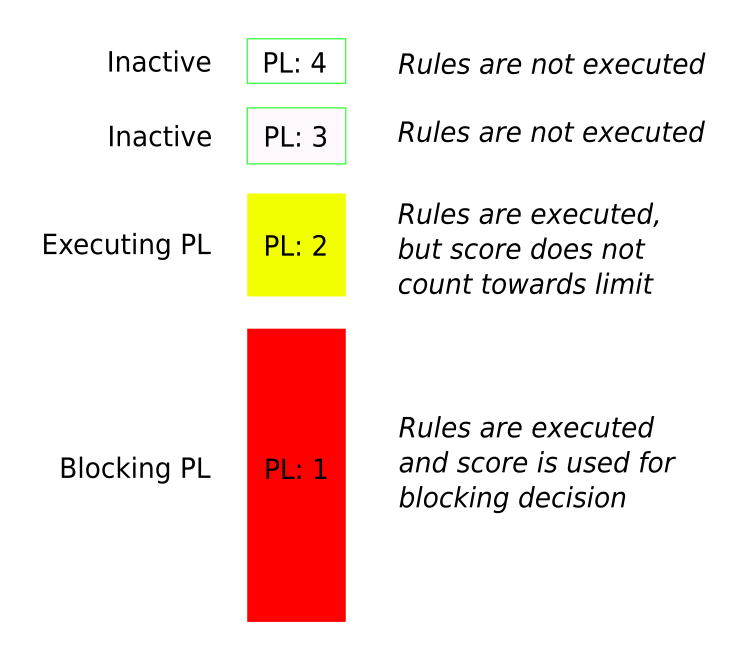
By the way, you can always lower the Paranoia Level (or Blocking Paranoia Level, if you will) and you will get fewer false positives, or none. The way the rule set is constructed, lowering the Paranoia Level always means fewer or no false positives; raising the Paranoia Level is likely to bring more false positives.
Coupling PL with GeoIP or Other Information (like a previous anomaly score)
The description above is all you need to know to run CRS successfully. However, there are options and ideas to couple the Paranoia Level setting with various pieces of information. Before we come to the end of this blog post, I will describe two such ideas along with their pros and cons.
Let’s say your customers are mostly local customers or they are limited to a certain region of the world that you can define via GeoIP (IP address-based geolocation). You do not want to exclude the rest of the world (your customers go on holiday from time to time), but you think a request coming from the far end of the planet is suspicious. One way to deal with this would be to assign a higher Paranoia Level to HTTP requests coming from said GeoLocation. Or rather
If GeoLocation == Local
set PL=1
Else
set PL=2
This works nicely and I have heard of people doing things this way. Personally, I have never gone to production with such a setup since it likely means you will tune away fewer false positives from PL 2. This is because your customers are local and non-local customers are seen as potential attackers, so you concentrate on PL 1 false positives and PL 2 does not receive the same amount of time and scrutiny.
Now should one of your customers indeed leave the local zone and use your service from abroad they will face new and unknown false positives and have a bad user experience. That is bad.
However, if you pay good attention to the false positives at PL 2 and you do the work to really tune them away, why not run PL 2 for everybody? This would give you a higher level of security for all requests with the same absence of false positives.
As you can see, a concept that looks cool at the beginning is not quite as cool if you think it through.
The second idea is very similar: when somebody triggers an Anomaly Score above 0 on a request (it does not matter whether the request exceeded the Anomaly Threshold or not) then you assign subsequent requests from that HTTP client to a higher initial Paranoia Level. So the default PL is 1, but if you trigger any rules at PL 1 then we assign you PL 2 for every subsequent rule with the help of ModSecurity’s persistent storage.
This is a neat concept and I think you could run this, even if I never did so personally. The ModSecurity persistent storage is at times a bit of a hassle, namely on heavy sites with a lot of traffic. But that can be acceptable and the concept is useful when you are 100% sure there are no false positives.
If you are 100% sure there are no false positives in your application, however, then why would you accept subsequent requests from said client at all? You have already identified it as an attacking client. In such a situation, it might be smarter to block the subsequent requests altogether, either via ModSecurity’s persistent storage or via a tool like fail2ban - and this I have done in production in a highly effective way. Alternatively, you could also send these requests to a pre-prepared sandbox and observe the behaviour of the client in your baited sandbox application. But that’s a topic for another blog post.
 Christian Folini / [@ChrFolini]
Christian Folini / [@ChrFolini]