OWASP CRS provides documentation for many of the aspects surrounding the project. This page provides an overview of the project and its documentation.
Info
Security issues regarding CRS can be submitted via email to security [ at ] coreruleset.org.
What is CRS?
OWASP® (Open Worldwide Application Security Project) CRS (previously Core Rule Set) is a free and open-source collection of rules that work with ModSecurity® and compatible web application firewalls (WAFs). These rules are designed to provide easy to use, generic attack detection capabilities, with a minimum of false positives (false alerts), to web applications as part of a well balanced defense-in-depth solution.
How to Get Involved
For information on how to join the vibrant community of CRS developers, start by checking out the project’s GitHub repository. When ready to make a contribution, have a read of the project’s contribution guidelines which are used to keep the project consistent, well managed, and of a high quality.
CRS Change Policy
The project endeavors not to make breaking changes in minor releases (i.e., 3.3.2). Instead, these releases fix bugs identified in the previous release.
New functionality and breaking changes are made in major releases (i.e., 3.3).
For information about what has changed in recent versions of the software, refer to the project’s CHANGES file on GitHub.
This documentation has been statically generated with Hugo. It uses the Hugo Relearn Theme.
License
OWASP CRS is a free and open-source set of security rules which use the Apache License 2.0. Although it was originally developed for ModSecurity’s SecRules language, the rule set can be, and often has been, freely modified, reproduced, and adapted for various commercial and non-commercial endeavors. The CRS project encourages individuals and organizations to contribute back to the OWASP CRS where possible.
Subsections of CRS Documentation
Getting Started
Subsections of Getting Started
CRS Installation
This guide aims to get a CRS installation up and running. This guide assumes that a compatible ModSecurity engine is already present and working. If unsure then refer to the extended install page for full details.
Downloading the Rule Set
The first step is to download CRS. The CRS project strongly recommends using a supported version.
For production environments, it is recommended to use the latest release, which is v4.25.0. For testing the bleeding edge CRS version, nightly releases are also provided.
Verifying Releases
Note
Releases are signed using the CRS project’s GPG key (fingerprint: 3600 6F0E 0BA1 6783 2158 8211 38EE ACA1 AB8A 6E72). Releases can be verified using GPG/PGP compatible tooling.
To retrieve the CRS project’s public key from public key servers using gpg, execute: gpg --keyserver pgp.mit.edu --recv 0x38EEACA1AB8A6E72 (this ID should be equal to the last sixteen hex characters in the fingerprint).
It is also possible to use gpg --fetch-key https://coreruleset.org/security.asc to retrieve the key directly.
The following steps assume that a *nix operating system is being used. Installation is similar on Windows but likely involves using a zip file from the CRS releases page.
To download the release file and the corresponding signature:
gpg --verify coreruleset-4.25.0.tar.gz.asc v4.25.0.tar.gz
gpg: Signature made Wed Jun 30 10:05:48 2021 -03
gpg: using RSA key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg: Good signature from "OWASP CRS <security@coreruleset.org>"[unknown]gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: 3600 6F0E 0BA1 678321588211 38EE ACA1 AB8A 6E72
If the signature was good then the verification succeeds. If a warning is displayed, like the above, it means the CRS project’s public key is known but is not trusted.
To trust the CRS project’s public key:
gpg --edit-key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg> trust
Your decision: 5(ultimate trust)Are you sure: Yes
gpg> quit
The result when verifying a release will then look like so:
gpg --verify coreruleset-4.25.0.tar.gz.asc v4.25.0.tar.gz
gpg: Signature made Wed Jun 30 15:05:48 2021 CEST
gpg: using RSA key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg: Good signature from "OWASP CRS <security@coreruleset.org>"[ultimate]
Installing the Rule Set
Extracting the Files
Once the rule set has been downloaded and verified, extract the rule set files to a well known location on the server. This will typically be somewhere in the web server directory.
The examples presented below demonstrate using Apache. For information on configuring Nginx or IIS see the extended install page.
Note that while it’s common practice to make a new modsecurity.d folder, as outlined below, this isn’t strictly necessary. The path scheme outlined is common on RHEL-based operating systems; the Apache path used may need to be adjusted to match the server’s installation.
mkdir /etc/crs4
tar -xzvf v4.25.0.tar.gz --strip-components 1 -C /etc/crs4
Now all the CRS files will be located below the /etc/crs4 directory.
Setting Up the Main Configuration File
After extracting the rule set files, the next step is to set up the main OWASP CRS configuration file. An example configuration file is provided as part of the release package, located in the main directory: crs-setup.conf.example.
Note
Other aspects of ModSecurity, particularly engine-specific parameters, are controlled by the ModSecurity “recommended” configuration rules, modsecurity.conf-recommended. This file comes packaged with ModSecurity itself.
In many scenarios, the default example CRS configuration will be a good enough starting point. It is, however, a good idea to take the time to look through the example configuration file before deploying it to make sure it’s right for a given environment.
Warning
In particular, Response rules are enabled by default. You must be aware that you may be vulnerable to RFDoS attacks, depending on the responses your application is sending back to the client. You could be vulnerable, if your responses from your application can contain user input. If an attacker can submit user input that is returned as part of a response, the attacker can craft the input in such a way that the response rules of the WAF will block responses containing that input for all clients. For example, a blog post might no longer be accessible because of the contents of a comment on the post. See this blog post about the problems you could face.
There is an experimental scanner that uses nuclei to find out if are affected. So if
you are unsure, first test your application before enabling the response rules, or risk accidentally blocking some valid responses.
Response rules can be easily disabled by uncommenting the rule with id 900500 in the crs-setup.conf file,
since CRS version 4.10.0.
The CRS team believes that the damage that can be caused by webshells and information leakage outweighs the damage of RFDos attacks, in general. Thus, the response rules remain active in the default configuration for now.
Once any settings have been changed within the example configuration file, as needed, it should be renamed to remove the .example portion, like so:
cd /etc/crs4
mv crs-setup.conf.example crs-setup.conf
Include-ing the Rule Files
The last step is to tell the web server where the rules are. This is achieved by include-ing the rule configuration files in the httpd.conf file. Again, this example demonstrates using Apache, but the process is similar on other systems (see the extended install page for details).
Now that everything has been configured, it should be possible to restart and begin using the OWASP CRS. The CRS rules typically require a bit of tuning with rule exclusions, depending on the site and web applications in question. For more information on tuning, see false positives and tuning.
systemctl restart httpd.service
Alternative: Using Containers
Another quick option is to use the official CRS pre-packaged containers. Docker, Podman, or any compatible container engine can be used. The official CRS images are published on Docker Hub and GitHub Container Repository. The image most often deployed is modsecurity-crs (owasp/modsecurity-crs from Docker Hub or ghcr.io/coreruleset/modsecurity-crs from GHCR): it already has everything needed to get up and running quickly.
The CRS project pre-packages both Apache and Nginx web servers along with the appropriate corresponding ModSecurity engine. More engines, like Coraza, will be added at a later date.
To protect a running web server, all that’s required is to get the appropriate image and set its configuration variables to make the WAF receives requests and proxies them to your backend server.
Below is an example docker compose file that can be used to pull the container images. If you don’t have compose installed, please read the installation instructions. All that needs to be changed is the BACKEND variable so that the WAF points to the backend server in question:
services:
modsec2-apache:
container_name: modsec2-apache
image: owasp/modsecurity-crs:apache
# if you are using Linux, you will need to uncomment the below line
# user: root
environment:
SERVERNAME: modsec2-apache
BACKEND: http://<backend server>
PORT: "80"
MODSEC_RULE_ENGINE: DetectionOnly
BLOCKING_PARANOIA: 2
TZ: "${TZ}"
ERRORLOG: "/var/log/error.log"
ACCESSLOG: "/var/log/access.log"
MODSEC_AUDIT_LOG_FORMAT: Native
MODSEC_AUDIT_LOG_TYPE: Serial
MODSEC_AUDIT_LOG: "/var/log/modsec_audit.log"
MODSEC_TMP_DIR: "/tmp"
MODSEC_RESP_BODY_ACCESS: "On"
MODSEC_RESP_BODY_MIMETYPE: "text/plain text/html text/xml application/json"
COMBINED_FILE_SIZES: "65535"
volumes:
ports:
- "80:80"
That’s all that needs to be done. Simply starting the container described above will instantly provide the protection of the latest stable CRS release in front of a given backend server or service. There are lots of additional variables that can be used to configure the container image and its behavior, so be sure to read the full documentation.
Verifying that the CRS is active
Always verify that CRS is installed correctly by sending a ‘malicious’ request to your site or application, for instance:
Depending on your configurated thresholds, this should be detected as a malicious request. If you use blocking mode, you should receive an Error 403. The request should also be logged to the audit log, which is usually in /var/log/modsec_audit.log.
Upgrading
Upgrading from CRS 3.x to CRS 4
The most impactful change is the removal of application exclusion packages in favor of a plugin system. If you had activated the exclusion packages in CRS 3, you should download the plugins for them and place them in the plugins subdirectory. We maintain the list of plugins in our Plugin Registry. You can find detailed information on working with plugins in our plugins documentation.
In terms of changes to the detection rules, the amount of changes is smaller than in the CRS 2—3 changeover. Most rules have only evolved slightly, so it is recommended that you keep any existing custom exclusions that you have made under CRS 3.
We recommend to start over by copying our crs-setup.conf.example to crs-setup.conf with a copy of your old file at hand, and re-do the customizations that you had under CRS 3.
Please note that we added a large number of new detections, and any new detection brings a certain risk of false alarms. Therefore, we recommend to test first before going live.
Upgrading from CRS 2.x to CRS 3
In general, you can update by unzipping our new release over your older one, and updating the crs-setup.conf file with any new settings. However, CRS 3.0 is a major rewrite, incompatible with CRS 2.x. Key setup variables have changed their name, and new features have been introduced. Your former modsecurity_crs_10_setup.conf file is thus no longer usable. We recommend you to start with a fresh crs-setup.conf file from scratch.
Most rule IDs have been changed to reorganize them into logical sections. This means that if you have written custom configuration with exclusion rules (e.g. SecRuleRemoveById, SecRuleRemoveTargetById, ctl:ruleRemoveById or ctl:ruleRemoveTargetById) you must renumber the rule numbers in that configuration. You can do this using the supplied utility util/id_renumbering/update.py or find the changes in util/id_renumbering/IdNumbering.csv.
However, a key feature of the CRS 3 is the reduction of false positives in the default installation, and many of your old exclusion rules may no longer be necessary. Therefore, it is a good option to start fresh without your old exclusion rules.
If you are experienced in writing exclusion rules for CRS 2.x, it may be worthwhile to try running CRS 3 in Paranoia Level 2 (PL2). This is a stricter mode, which blocks additional attack patterns, but brings a higher number of false positives — in many situations the false positives will be comparable with CRS 2.x. This paranoia level however will bring you a higher protection level than CRS 2.x or a CRS 3 default install, so it can be worth the investment.
Extended Install
All the information needed to properly install CRS is presented on this page. The installation concepts are expanded upon and presented in more detail than the quick start guide.
Contact Us
To contact the CRS project with questions or problems, reach out via the project’s Google group or Slack channel (for Slack channel access, use this link to get an invite).
Prerequisites
Installing the CRS isn’t very difficult but does have one major requirement: a compatible engine. The reference engine used throughout this page is ModSecurity.
Note
In order to successfully run CRS 3.x using ModSecurity it is recommended to use the latest version available. For Nginx use the 3.x branch of ModSecurity, and for Apache use the latest 2.x branch.
Installing a Compatible WAF Engine
Two different methods to get an engine up and running are presented here:
using the chosen engine as provided and packaged by the OS distribution
compiling the chosen engine from source
A ModSecurity installation is presented in the examples below, however the install documentation for the Coraza engine can be found here.
Option 1: Installing Pre-Packaged ModSecurity
ModSecurity is frequently pre-packaged and is available from several major Linux distributions.
Debian: Friends of the CRS project DigitalWave package and, most importantly, keep ModSecurity updated for Debian and derivatives.
Fedora: Execute dnf install mod_security for Apache + ModSecurity v2.
RHEL compatible: Install EPEL and then execute yum install mod_security.
Distributions might not update their ModSecurity releases frequently.
As a result, it is quite likely that a distribution’s version of ModSecurity may be missing important features or may even contain security vulnerabilities. Additionally, depending on the package and package manager used, the ModSecurity configuration will be laid out slightly differently.
As the different engines and distributions have different layouts for their configuration, to simplify the documentation presented here the prefix <web server config>/ will be used from this point on.
Examples of <web server config>/ include:
/etc/apache2 in Debian and derivatives
/etc/httpd in RHEL and derivatives
/usr/local/apache2 if Apache was compiled from source using the default prefix
C:\Program Files\ModSecurity IIS\ (or Program Files(x86), depending on configuration) on Windows
/etc/nginx
Option 2: Compiling ModSecurity From Source
Compiling ModSecurity is easy, but slightly outside the scope of this document. For information on how to compile ModSecurity, refer to:
Note that the following configurations are not supported. They do not work as expected. The CRS project recommendation is to avoid these setups:
Nginx with ModSecurity v2
Apache with ModSecurity v3
Testing the Compiled Module
Once ModSecurity has been compiled, there is a simple test to see if the installation is working as expected. After compiling from source, use the appropriate directive to load the newly compiled module into the web server. For example:
The initial configuration file is modsecurity_iis.conf. This file will be parsed by ModSecurity for both ModSecurity directives and 'Include' directives.
Additionally, in the Event Viewer, under Windows Logs\Application, it should be possible to see a new log entry showing ModSecurity being successfully loaded.
At this stage, the ModSecurity on IIS setup is working and new directives can be placed in the configuration file as needed.
Downloading OWASP CRS
With a compatible WAF engine installed and working, the next step is typically to download and install the OWASP CRS. The CRS project strongly recommends using a supported version.
For production environments, it is recommended to use the latest release, which is v4.25.0. For testing the bleeding edge CRS version, nightly releases are also provided.
Verifying Releases
Note
Releases are signed using the CRS project’s GPG key (fingerprint: 3600 6F0E 0BA1 6783 2158 8211 38EE ACA1 AB8A 6E72). Releases can be verified using GPG/PGP compatible tooling.
To retrieve the CRS project’s public key from public key servers using gpg, execute: gpg --keyserver pgp.mit.edu --recv 0x38EEACA1AB8A6E72 (this ID should be equal to the last sixteen hex characters in the fingerprint).
It is also possible to use gpg --fetch-key https://coreruleset.org/security.asc to retrieve the key directly.
The following steps assume that a *nix operating system is being used. Installation is similar on Windows but likely involves using a zip file from the CRS releases page.
To download the release file and the corresponding signature:
gpg --verify coreruleset-4.25.0.tar.gz.asc v4.25.0.tar.gz
gpg: Signature made Wed Jun 30 10:05:48 2021 -03
gpg: using RSA key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg: Good signature from "OWASP CRS <security@coreruleset.org>"[unknown]gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: 3600 6F0E 0BA1 678321588211 38EE ACA1 AB8A 6E72
If the signature was good then the verification succeeds. If a warning is displayed, like the above, it means the CRS project’s public key is known but is not trusted.
To trust the CRS project’s public key:
gpg --edit-key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg> trust
Your decision: 5(ultimate trust)Are you sure: Yes
gpg> quit
The result when verifying a release will then look like so:
gpg --verify coreruleset-4.25.0.tar.gz.asc v4.25.0.tar.gz
gpg: Signature made Wed Jun 30 15:05:48 2021 CEST
gpg: using RSA key 36006F0E0BA167832158821138EEACA1AB8A6E72
gpg: Good signature from "OWASP CRS <security@coreruleset.org>"[ultimate]
With the CRS release downloaded and verified, the rest of the set up can continue.
Setting Up OWASP CRS
OWASP CRS contains a setup file that should be reviewed prior to completing set up. The setup file is the only configuration file within the root ‘coreruleset-4.25.0’ folder and is named crs-setup.conf.example. Examining this configuration file and reading what the different options are is highly recommended.
At a minimum, keep in mind the following:
CRS does not configure features such as the rule engine, audit engine, logging, etc. This task is part of the initial engine setup and is not a job for the rule set. For ModSecurity, if not already done, see the recommended configuration.
Decide what ModSecurity should do when it detects malicious activity, e.g., drop the packet, return a 403 Forbidden status code, issue a redirect to a custom page, etc.
Make sure to configure the anomaly scoring thresholds. For more information see Anomaly.
By default, the CRS rules will consider many issues with different databases and languages. If running in a specific environment, e.g., without any SQL database services present, it is probably a good idea to limit this behavior for performance reasons.
Make sure to add any HTTP methods, static resources, content types, or file extensions that are needed, beyond the default ones listed.
Once reviewed and configured, the CRS configuration file should be renamed by changing the file suffix from .example to .conf:
mv crs-setup.conf.example crs-setup.conf
In addition to crs-setup.conf.example, there are two other “.example” files within the CRS repository. These are:
These files are designed to provide the rule maintainer with the ability to modify rules (see false positives and tuning) without breaking forward compatibility with rule set updates. These two files should be renamed by removing the .example suffix. This will mean that installing updates will not overwrite custom rule exclusions. To rename the files in Linux, use a command similar to the following:
The engine should support the Include directive out of the box. This directive tells the engine to parse additional files for directives. The question is where to put the CRS rules folder in order for it to be included.
Looking at the CRS files, there are quite a few “.conf” files. While the names attempt to do a good job at describing what each file does, additional information is available in the rules section.
Includes for Apache
It is recommended to create a folder specifically to contain the CRS rules. In the example presented here, a folder named modsecurity.d has been created and placed within the root <web server config>/ directory. When using Apache, wildcard notation can be used to vastly simplify the Include rules. Simply copying the cloned directory into the modsecurity.d folder and specifying the appropriate Include directives will install OWASP CRS. In the example below, the modsecurity.conf file has also been included, which includes recommended configurations for ModSecurity.
<IfModulesecurity2_module> Include modsecurity.d/modsecurity.conf
Include /etc/crs4/crs-setup.conf
Include /etc/crs4/plugins/*-config.conf
Include /etc/crs4/plugins/*-before.conf
Include /etc/crs4/rules/*.conf
Include /etc/crs4/plugins/*-after.conf
</IfModule>
Includes for Nginx
Nginx will include files from the Nginx configuration directory (/etc/nginx or /usr/local/nginx/conf/, depending on the environment). Because only one ModSecurityConfig directive can be specified within nginx.conf, it is recommended to name that file modsec_includes.conf and include additional files from there. In the example below, the cloned coreruleset folder was copied into the Nginx configuration directory. From there, the appropriate include directives are specified which will include OWASP CRS when the server is restarted. In the example below, the modsecurity.conf file has also been included, which includes recommended configurations for ModSecurity.
You will also need to include the plugins you want along with your CRS installation.
Using Containers
The CRS project maintains a set of ‘CRS with ModSecurity’ Docker images.
A full operational guide on how to use and deploy these images will be written in the future. In the meantime, refer to the GitHub README page for more information on how to use these official container images.
A Docker image supporting the latest stable CRS release on:
the latest stable ModSecurity v2 on Apache
the latest stable ModSecurity v3 on Nginx
Engine and Integration Options
CRS runs on WAF engines that are compatible with a subset of ModSecurity’s SecLang configuration language. There are several options outside of ModSecurity itself, namely cloud offerings and content delivery network (CDN) services. There is also an open-source alternative to ModSecurity in the form of the new Coraza WAF engine.
Compatible Free and Open-Source WAF Engines
ModSecurity v2
ModSecurity v2, originally a security module for the Apache web server, is the reference implementation for CRS.
ModSecurity 2.9.x passes 100% of the CRS unit tests on the Apache platform.
When running ModSecurity, this is the option that is practically guaranteed to work with most documentation and know-how all around.
ModSecurity is released under the Apache License 2.0, and the project now lives under the OWASP Foundation umbrella.
ModSecurity v3, also known as libModSecurity, is a re-implementation of ModSecurity v3 with an architecture that is less dependent on the web server. The connection between the standalone ModSecurity and the web server is made using a lean connector module.
As of spring 2021, only the Nginx connector module is really usable in production.
ModSecurity v3 fails with 2-4% of the CRS unit tests due to bugs and implementation gaps. Nginx + ModSecurity v3 also suffers from performance problems when compared to the Apache + ModSecurity v2 platform. This may be surprising for people familiar with the high performance of Nginx.
ModSecurity v3 is used in production together with Nginx, but the CRS project recommends to use the ModSecurity v2 release line with Apache.
ModSecurity is released under the Apache License 2.0. It was primarily developed by Spiderlabs, an entity within the company Trustwave. In summer 2021, Trustwave announced their plans to end development of ModSecurity in 2024. On Jan 25th 2024, the project was transferred to the OWASP Foundation.
OWASP Coraza WAF is meant to provide an open-source alternative to the two ModSecurity release lines.
Coraza passes 100% of the CRS v4 test suite and is thus fully compatible with CRS.
Coraza has been developed in Go and currently runs on the Caddy and Traefik platforms. Additional ports are being developed and the developers also seek to bring Coraza to Nginx and, eventually, Apache. In parallel to this expansion, Coraza will be developed further with its own feature set.
To learn more about CRS and Coraza, read this CRS blog post which introduces Coraza.
Commercial WAF Appliances
Dozens of commercial WAFs, both virtual and hardware-based, offer CRS as part of their service. Many of them use ModSecurity underneath, or some alternative implementation (although this is rare on the WAF appliance approach). Most of these commercial WAFs either don’t offer the full feature set of CRS or they don’t make it easily accessible. With some of these companies, there is often also a lack of CRS experience and knowledge.
The CRS project recommends evaluating these commercial appliance-based offerings in a holistic way before buying a license.
In light of the many, many appliance offerings on the market and the CRS project’s relatively limited exposure, only a few offerings are listed here.
HAProxy Technologies
HAProxy Technologies embeds ModSecurity v3 in three of its products via the Libmodsecurity module. ModSecurity is included with: HAProxy Enterprise, HAProxy ALOHA, and HAProxy Enterprise Kubernetes Ingress Controller.
There is also a Coraza SPOA solution that works with HAProxy.
Kemp/Progressive LoadMaster
The Kemp LoadMaster is a popular load balancer that integrates ModSecurity v2 and CRS in a typical way. It goes further than the competition with the support of most CRS features.
The load balancer appliance from Loadbalancer.org features WAF functionality based on Apache + ModSecurity v2 + CRS, sandwiched by HAProxy for load balancing. It’s available as a hardware, virtual, and cloud appliance.
Existing CRS Integrations: Cloud and CDN Offerings
Most big cloud providers and CDNs provide a CRS offering. While originally these were mostly based on ModSecurity, over time they have all moved to alternative (usually proprietary) implementations of ModSecurity’s SecLang configuration language, or they transpose the CRS rules written in SecLang into their own domain specific language (DSL).
The CRS project has some insight into some of these platforms and is in touch with most of these providers. The exact specifics are not really known, however, but what is known is that almost all of these integrators compromised and provide a subset of CRS rules and a subset of features, in the interests of ease of integration and operation.
Info
The CRS Status page project will be testing cloud and CDN offerings. As part of this effort, the CRS project will be documenting the results and even publishing code on how to quickly get started using CRS in CDN/cloud providers. This status page project is in development as of spring 2022.
A selection of these platforms are listed below, along with links to get more info.
AWS WAF
Note
AWS provides a rule set called the “Core rule set (CRS) managed rule group” which “…provides protection against… commonly occurring vulnerabilities described in OWASP publications such as OWASP Top 10.”
The CRS project does not believe that the AWS WAF “core rule set” is based on or related to OWASP CRS.
Cloudflare WAF
Cloudflare WAF supports CRS as one of its WAF rule sets. Documentation on how to use it can be found in Cloudflare’s documentation.
Fastly
Fastly has offered CRS as part of their Fastly WAF for several years, but they have started to migrate their existing customers to the recently acquired Signal Sciences WAF. Interestingly, Fastly is transposing CRS rules into their own Varnish-based WAF engine. Unfortunately, documentation on their legacy WAF offering has been removed.
Google Cloud Armor
Google integrates CRS into its Cloud Armor WAF offering. Google runs the CRS rules on their own WAF engine. As of April 2026, Google offers version 4.22 of CRS in preview mode (must be enabled specifically), with version 3.3 offered in general release.
Azure Application Gateways can be configured to use the WAFv2 and managed rules with different versions of CRS. Azure provides the 3.2, 3.1, 3.0, and 2.2.9 CRS versions. We recommend using version 3.2 (see our security policy for details on supported CRS versions).
Oracle WAF
The Oracle WAF is a cloud-based offering that includes CRS. To learn more, read Oracle’s WAF documentation.
Alternative Use Cases
Outside of the narrower implementation of a WAF, CRS can also be found in different security-related setups.
How CRS Works
Deep dive into core CRS concepts in this chapter.
Subsections of How CRS Works
Anomaly Scoring
CRS 3 is designed as an anomaly scoring rule set. This page explains what anomaly scoring is and how to use it.
Overview of Anomaly Scoring
Anomaly scoring, also known as “collaborative detection”, is a scoring mechanism used in CRS. It assigns a numeric score to HTTP transactions (requests and responses), representing how ‘anomalous’ they appear to be. Anomaly scores can then be used to make blocking decisions. The default CRS blocking policy, for example, is to block any transaction that meets or exceeds a defined anomaly score threshold.
How Anomaly Scoring Mode Works
Anomaly scoring mode combines the concepts of collaborative detection and delayed blocking. The key idea to understand is that the inspection/detection rule logic is decoupled from the blocking functionality.
Individual rules designed to detect specific types of attacks and malicious behavior are executed. If a rule matches, no immediate disruptive action is taken (e.g. the transaction is not blocked). Instead, the matched rule contributes to a transactional anomaly score, which acts as a running total. The rules just handle detection, adding to the anomaly score if they match. In addition, an individual matched rule will typically log a record of the match for later reference, including the ID of the matched rule, the data that caused the match, and the URI that was being requested.
Once all of the rules that inspect request data have been executed, blocking evaluation takes place. If the anomaly score is greater than or equal to the inbound anomaly score threshold then the transaction is denied. Transactions that are not denied continue on their journey.
Continuing on, once all of the rules that inspect response data have been executed, a second round of blocking evaluation takes place. If the outbound anomaly score is greater than or equal to the outbound anomaly score threshold, then the response is not returned to the user. (Note that in this case, the request is fully handled by the backend or application; only the response is stopped.)
Info
Having separate inbound and outbound anomaly scores and thresholds allows for request data and response data to be inspected and scored independently.
Summary of Anomaly Scoring Mode
To summarize, anomaly scoring mode in the CRS works like so:
Execute all request rules
Make a blocking decision using the inbound anomaly score threshold
Execute all response rules
Make a blocking decision using the outbound anomaly score threshold
The Anomaly Scoring Mechanism In Action
As described, individual rules are only responsible for detection and inspection: they do not block or deny transactions. If a rule matches then it increments the anomaly score. This is done using ModSecurity’s setvar action.
Below is an example of a detection rule which matches when a request has a Content-Length header field containing something other than digits. Notice the final line of the rule: it makes use of the setvar action, which will increment the anomaly score if the rule matches:
Notice that the anomaly score variable name has the suffix pl1. Internally, CRS keeps track of anomaly scores on a perparanoia level basis. The individual paranoia level anomaly scores are added together before each round of blocking evaluation takes place, allowing the total combined inbound or outbound score to be compared to the relevant anomaly score threshold.
Tracking the anomaly score per paranoia level allows for clever scoring mechanisms to be employed, such as the executing paranoia level feature.
The rules files REQUEST-949-BLOCKING-EVALUATION.conf and RESPONSE-959-BLOCKING-EVALUATION.conf are responsible for executing the inbound (request) and outbound (response) rounds of blocking evaluation, respectively. The rules in these files calculate the total inbound or outbound transactional anomaly score and then make a blocking decision, by comparing the result to the defined threshold and taking blocking action if required.
Configuring Anomaly Scoring Mode
The following settings can be configured when using anomaly scoring mode:
Anomaly score thresholds
Severity levels
Early blocking
If using a native CRS installation on a web application firewall, these settings are defined in the file crs-setup.conf. If running CRS where it has been integrated into a commercial product or CDN then support varies. Some vendors expose these settings in the GUI while other vendors require custom rules to be written which set the necessary variables. Unfortunately, there are also vendors that don’t allow these settings to be configured at all.
Anomaly Score Thresholds
An anomaly score threshold is the cumulative anomaly score at which an inbound request or an outbound response will be blocked.
Most detected inbound threats carry an anomaly score of 5 (by default), while smaller violations, e.g. protocol and standards violations, carry lower scores. An anomaly score threshold of 7, for example, would require multiple rule matches in order to trigger a block (e.g. one “critical” rule scoring 5 plus a lesser-scoring rule, in order to reach the threshold of 7). An anomaly score threshold of 10 would require at least two “critical” rules to match, or a combination of many lesser-scoring rules. Increasing the anomaly score thresholds makes the CRS less sensitive and hence less likely to block transactions.
Rule coverage should be taken into account when setting anomaly score thresholds. Different CRS rule categories feature different numbers of rules. SQL injection, for example, is covered by more than 50 rules. As a result, a real world SQLi attack can easily gain an anomaly score of 15, 20, or even more. On the other hand, a rare protocol attack might only be covered by a single, specific rule. If such an attack only causes the one specific rule to match then it will only gain an anomaly score of 5. If the inbound anomaly score threshold is set to anything higher than 5 then attacks like the one described will not be stopped. As such, a CRS installation should aim for an inbound anomaly score threshold of 5.
Warning
Increasing the anomaly score threshold above the defaults (5 for requests, 4 for responses), will allow a substantial number of attacks to bypass CRS and will impede the ability of critical rules to function correctly, such as LFI, RFI, RCE, and data-exfiltration rules. The anomaly score threshold should only ever be increased temporarily during false-positive tuning.
Some WAF vendors (such as Cloudflare) set the default anomaly score well above our defaults. This is not a proper implementation of CRS, and will result in bypasses.
Info
An outbound anomaly score threshold of 4 (the default) will block a transaction if any single response rule matches.
Tip
A common practice when working with a new CRS deployment is to start in blocking mode from the very beginning with very high anomaly score thresholds (even as high as 10000). The thresholds can be gradually lowered over time as an iterative process.
This tuning method was developed and advocated by Christian Folini, who documented it in detail, along with examples, in a popular tutorial titled Handling False Positives with OWASP CRS.
CRS uses two anomaly score thresholds, which can be defined using the variables listed below:
Threshold
Variable
Inbound anomaly score threshold
tx.inbound_anomaly_score_threshold
Outbound anomaly score threshold
tx.outbound_anomaly_score_threshold
A simple way to set these thresholds is to uncomment and use rule 900110:
Each CRS rule has an associated severity level. Different severity levels have different anomaly scores associated with them. This means that different rules can increment the anomaly score by different amounts if the rules match.
The four severity levels and their default anomaly scores are:
Severity Level
Default Anomaly Score
CRITICAL
5
ERROR
4
WARNING
3
NOTICE
2
For example, by default, a single matching CRITICAL rule would increase the anomaly score by 5, while a single matching WARNING rule would increase the anomaly score by 3.
The default anomaly scores are rarely ever changed. It is possible, however, to set custom anomaly scores for severity levels. To do so, uncomment rule 900100 and set the anomaly scores as desired:
The CRS makes use of a ModSecurity feature called macro expansion to propagate the value of the severity level anomaly scores throughout the entire rule set.
Early Blocking
Early blocking is an optional setting which can be enabled to allow blocking decisions to be made earlier than usual.
As summarized previously, anomaly scoring mode works like so:
Execute all request rules
Make a blocking decision using the inbound anomaly score threshold
Execute all response rules
Make a blocking decision using the outbound anomaly score threshold
The early blocking option takes advantage of the fact that the request and response rules are actually split across different phases. A more detailed overview of anomaly scoring mode looks like so:
Execute all phase 1 (request header) rules
Execute all phase 2 (request body) rules
Make a blocking decision using the inbound anomaly score threshold
Execute all phase 3 (response header) rules
Execute all phase 4 (response body) rules
Make a blocking decision using the outbound anomaly score threshold
More data from a transaction becomes available for inspection in each subsequent processing phase. In phase 1 the request headers are available for inspection. Detection rules that are only concerned with request headers are executed here. In phase 2 the request body also becomes available for inspection. Rules that need to inspect the request body, perhaps in addition to request headers, are executed here.
If a transaction’s anomaly score already meets or exceeds the inbound anomaly score threshold by the end of phase 1 (due to causing phase 1 rules to match) then, in theory, the phase 2 rules don’t need to be executed. This saves the time and resources it would take to process the detection rules in phase 2 and also protects the server from being attacked when handling the body of the request. The majority of CRS rules take place in phase 2, which is also where the request body inspection rules are located. When dealing with large request bodies, it may be worthwhile to avoid executing the phase 2 rules in this way. The same logic applies to blocking responses that have already met the outbound anomaly score threshold in phase 3, before reaching phase 4. This saves the time and resources required to execute the phase 4 rules, which inspect the response body.
Early blocking makes this possible by inserting two additional rounds of blocking evaluation: one after the phase 1 detection rules have finished executing, and another after the phase 3 detection rules:
Execute all phase 1 (request header) rules
Make an early blocking decision using the inbound anomaly score threshold
Execute all phase 2 (request body) rules
Make a blocking decision using the inbound anomaly score threshold
Execute all phase 3 (response header) rules
Make an early blocking decision using the outbound anomaly score threshold
Execute all phase 4 (response body) rules
Make a blocking decision using the outbound anomaly score threshold
Info
More information about processing phases can be found in the processing phases section of the ModSecurity Reference Manual.
Warning
The early blocking option has a major drawback to be aware of: it can cause potential alerts to be hidden.
If a transaction is blocked early then its body is not inspected. For example, if a transaction is blocked early at the end of phase 1 (the request headers phase) then the body of the request is never inspected. If the early blocking option is not enabled, it’s possible that such a transaction would proceed to cause phase 2 rules to match. Early blocking hides these potential alerts. The same applies to responses that trigger an early block: it’s possible that some phase 4 rules would match if early blocking were not enabled.
Using the early blocking option results in having less information to work with, due to fewer rules being executed. This may mean that the full picture is not present in log files when looking back at attacks and malicious traffic. It can also be a problem when dealing with false positives: tuning away a false positive in phase 1 will allow the same request to proceed to the next phase the next time it’s issued (instead of being blocked at the end of phase 1). The problem is that now, with the request making it past phase 1, more, previously “hidden” false positives may appear in phase 2.
Warning
If early blocking is not enabled, there’s a chance that the web server will interfere with the handling of a request between phases 1 and 2. Take the example where the Apache web server issues a redirect to a new location. With a request that violates CRS rules in phase 1, this may mean that the request has a higher anomaly score than the defined threshold but it gets redirected away before blocking evaluation happens.
Enabling the Early Blocking Option
If using a native CRS installation on a web application firewall, the early blocking option can be enabled in the file crs-setup.conf. This is done by uncommenting rule 900120, which sets the variable tx.early_blocking to 1 in order to enable early blocking. CRS otherwise gives this variable a default value of 0, meaning that early blocking is disabled by default.
If running CRS where it has been integrated into a commercial product or CDN then support for the early blocking option varies. Some vendors may allow it to be enabled through the GUI, through a custom rule, or they might not allow it to be enabled at all.
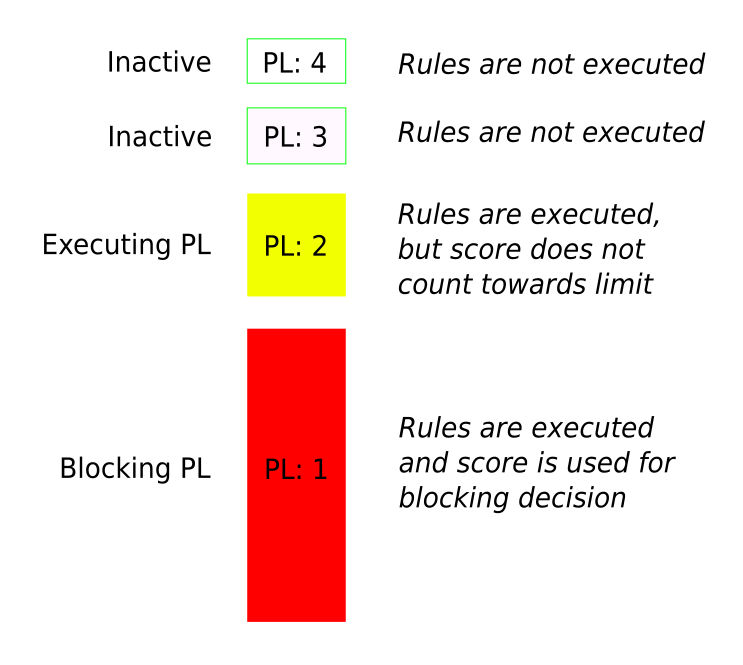
Paranoia Levels
Paranoia levels are an essential concept when working with CRS. This page explains the concept behind paranoia levels and how to work with them on a practical level.
Introduction to Paranoia Levels
The paranoia level (PL) makes it possible to define how aggressive CRS is. Paranoia level 1 (PL 1) provides a set of rules that hardly ever trigger a false alarm (ideally never, but it can happen, depending on the local setup). PL 2 provides additional rules that detect more attacks (these rules operate in addition to the PL 1 rules), but there’s a chance that the additional rules will also trigger new false alarms over perfectly legitimate HTTP requests.
This continues at PL 3, where more rules are added, namely for certain specialized attacks. This leads to even more false alarms. Then at PL 4, the rules are so aggressive that they detect almost every possible attack, yet they also flag a lot of legitimate traffic as malicious.
A higher paranoia level makes it harder for an attacker to go undetected. Yet this comes at the cost of more false positives: more false alarms. That’s the downside to running a rule set that detects almost everything: your business / service / web application is also disrupted.
When false positives occur they need to be tuned away. In ModSecurity parlance: rule exclusions need to be written. A rule exclusion is a rule that disables another rule, either disabled completely or disabled partially only for certain parameters or for certain URIs. This means the rule set remains intact yet the CRS installation is no longer affected by the false positives.
Note
Depending on the complexity of the service (web application) in question and on the paranoia level, the process of writing rule exclusions can be a substantial amount of work.
This page won’t explore the problem of handling false positives further: for more information on this topic, see the appropriate chapter or refer to the tutorials at netnea.com.
Description of the Four Paranoia Levels
The CRS project views the four paranoia levels as follows:
Paranoia Level
Description
1
Baseline security with a minimal need to tune away false positives. This is CRS for everybody running an HTTP server on the internet. Please report any false positives encountered with a PL 1 system via GitHub.
2
Rules that are adequate when real user data is involved. Perhaps an off-the-shelf online shop. Expect to encounter false positives and learn how to tune them away.
3
Online banking level security with lots of false positives. From a project perspective, false positives are accepted and expected here, so it’s important to learn how to write rule exclusions.
4
Rules that are so strong (or paranoid) they’re adequate to protect the “crown jewels”. To be used at one’s own risk: be prepared to face a large number of false positives.
Choosing an Appropriate Paranoia Level
It’s important to think about a service’s security requirements. The difference between protecting a personal website and the admin gateway controlling access to an enterprise’s Active Directory are very different. The paranoia level needs to be chosen accordingly, while also considering the resources (time) required to tune away false positives at higher paranoia levels.
Running at the highest paranoia level, PL 4, may seem appealing from a security standpoint, but it could take many weeks to tune away the false positives encountered. It is crucial to have enough time to fully deal with all false positives.
Warning
Failure to properly tune an installation runs the risk of exposing users to a vast number of false positives. This can lead to a poor user experience, and might ultimately lead to a decision to completely disable CRS. As such, setting a high PL in blocking mode without adequate tuning to deal with false positives is very risky.
If working in an enterprise environment, consider developing an internal policy to map the risk levels and security needs of different assets to the minimum acceptable paranoia level to be used for them, for example:
Risk Class 0: No personal data involved → PL 1
Risk Class 1: Personal data involved, e.g. names and addresses → PL 2
Risk Class 2: Sensitive data involved, e.g. financial/banking data; highest risk class → PL 3
Setting the Paranoia Level
If using a native CRS installation on a web application firewall, the paranoia level is defined by setting the variable tx.paranoia_level in the file crs-setup.conf. This is done in rule 900000, but technically the variable can be set in the Apache or Nginx configuration instead.
If running CRS where it has been integrated into a commercial product or CDN then support varies. Some vendors expose the PL setting in the GUI while other vendors require a custom rule to be written that sets tx.paranoia_level. Unfortunately, there are also vendors that don’t allow the PL to be set at all. (The CRS project considers this to be an incomplete CRS integration, since paranoia levels are a defining feature of CRS.)
How Paranoia Levels Relate to Anomaly Scoring
It’s important to understand that paranoia levels and CRS anomaly scoring (the CRS anomaly threshold/limit) are two entirely different things with no direct connection. The paranoia level controls the number of rules that are enabled while the anomaly threshold defines how many rules can be triggered before a request is blocked.
At the conceptual level, these two ideas could be mixed if the goal was to create a particularly granular security concept. For example, saying “we define the anomaly threshold to be 10, but we compensate for this by running at paranoia level 3, which we acknowledge brings more rule alerts and higher anomaly scores.”
This is technically correct but it overlooks the fact that there are attack categories where CRS scores very low. For example, there is a plan to introduce a new rule to detect POP3 and IMAP injections: this will be a single rule, so, under normal circumstances, an IMAP injection would never score more than 5. Therefore, an installation running at an anomaly threshold of 10 could never block an IMAP injection, even if running at PL 3. In light of this, it’s generally advised to keep things simple and separate: a CRS installation should aim for an anomaly threshold of 5 and a paranoia level as deemed appropriate.
Moving to a Higher Paranoia Level
Introducing the Executing Paranoia Level
Consider an example successful CRS installation: it operates at paranoia level 1, a handful of rule exclusions are in place to deal with false positives, and the inbound anomaly score threshold is set to 5 which blocks would-be attackers immediately. Things are running smoothly at paranoia level 1, but imagine that there’s now a requirement to increase the level of security by raising the paranoia level to 2. Moving to PL 2 will almost certainly cause new false positives: given the strict anomaly score threshold of 5, these will likely cause legitimate users to be blocked.
There’s a simple, but risky, way to raise the paranoia level of a working and tuned CRS installation: raise the anomaly score threshold for a period of time, in order to account for the additional false positives that are anticipated. Raising the anomaly score threshold will allow through attacks that would have been blocked previously. The idea of decreasing security in order to improve it is counter-intuitive, as well as being bad practice.
There is a better solution. First, think of the paranoia level as being the “blocking paranoia level”. The rules enabled in the blocking paranoia level count towards the anomaly score threshold, which is used to determine whether or not to block a given request. Now introduce an additional paranoia level: the “executing paranoia level”. By default, the executing paranoia level is automatically set to be equal to the blocking paranoia level. If, however, the executing paranoia level is set to be higher than the blocking paranoia level then the additional rules from the higher paranoia level are executed but will never count towards the anomaly score threshold used to make the blocking decision.
Example: Blocking paranoia level of 1 and executing paranoia level of 2
The executing paranoia level allows rules from a higher paranoia level to be run, and potentially to trigger false positives, without increasing the probability of blocking legitimate users. Any new false positives can then be tuned away using rule exclusions. Once ready and with all the new rule exclusions in place, the blocking paranoia level can then be raised to match the executing paranoia level. This approach is a flexible and secure way to raise the paranoia level on a working production system without the risk of new false positives blocking users in error.
Moving to a Lower Paranoia Level
It is always possible to lower the paranoia level in order to experience fewer false positives, or none at all. The way that the rule set is constructed, lowering the paranoia level always means fewer or no false positives; raising the paranoia level is very likely to introduce more false positives.
Further Reading
For a slightly longer explanation of paranoia levels, please refer to our blog post on the subject. The blog post also discusses the pros and cons of dynamically setting the paranoia level on a per-request basis, firstly by geolocation (i.e. a lower PL for domestic traffic and a higher PL for non-domestic traffic) and secondly based on previous behavior (i.e. a user is dealt with at PL 1, but if they ever trigger a rule then they’re handled at PL 2 for all future requests).
False Positives and Tuning
When a genuine transaction causes a rule from CRS to match in error it is described as a false positive. False positives need to be tuned away by writing rule exclusions, as this page explains.
What are False Positives?
CRS provides generic attack detection capabilities. A fresh CRS deployment has no awareness of the web services that may be running behind it, or the quirks of how those services work. It is possible that genuine transactions may cause some CRS rules to match in error, if the transactions happen to match one of the generic attack behaviors or patterns that are being detected. Such a match is referred to as a false positive, or false alarm.
False positives are particularly likely to happen when operating at higher paranoia levels. While paranoia level 1 is designed to cause few, ideally zero, false positives, higher paranoia levels are increasingly likely to cause false positives. Each successive paranoia level introduces additional rules, with higher paranoia levels adding more aggressive rules. As such, the higher the paranoia level is the more likely it is that false positives will occur. That is the cost of the higher security provided by higher paranoia levels: the additional time it takes to tune away the increasing number of false positives.
Example False Positive
Imagine deploying the CRS in front of a WordPress instance. The WordPress engine features the ability to add HTML to blog posts (as well as JavaScript, if you’re an administrator). Internally, WordPress has rules controlling which HTML tags are allowed to be used. This list of allowed tags has been studied heavily by the security community and it’s considered to be a secure mechanism.
Consider the CRS inspecting a request with a URL like the following:
At paranoia level 2, the wp_post query string parameter would trigger a match against an XSS attack rule due to the presence of HTML tags. CRS is unaware that the problem is properly mitigated on the server side and, as a result, the request causes a false positive and may be blocked. The false positive may generate an error log line like the following:
[Wed Jan 01 00:00:00.123456 2022] [:error] [pid 2357:tid 140543564093184] [client 10.0.0.1:0] [client 10.0.0.1] ModSecurity: Warning. Pattern match "<(?:a|abbr|acronym|address|applet|area|audioscope|b|base|basefront|bdo|bgsound|big|blackface|blink|blockquote|body|bq|br|button|caption|center|cite|code|col|colgroup|comment|dd|del|dfn|dir|div|dl|dt|em|embed|fieldset|fn|font|form|frame|frameset|h1|head ..." at ARGS:wp_post. [file "/etc/crs/rules/REQUEST-941-APPLICATION-ATTACK-XSS.conf"] [line "783"] [id "941320"] [msg "Possible XSS Attack Detected - HTML Tag Handler"] [data "Matched Data: <h1> found within ARGS:wp_post: <h1>welcome to my blog</h1>"] [severity "CRITICAL"] [ver "OWASP_CRS/3.3.2"] [tag "application-multi"] [tag "language-multi"] [tag "platform-multi"] [tag "attack-xss"] [tag "OWASP_CRS"] [tag "capec/1000/152/242/63"] [tag "PCI/6.5.1"] [tag "paranoia-level/2"] [hostname "www.example.com"] [uri "/"] [unique_id "Yad-7q03dV56xYsnGhYJlQAAAAA"]
This example log entry provides lots of information about the rule match. Some of the key pieces of information are:
The message from ModSecurity, which explains what happened and where:
ModSecurity: Warning. Pattern match "<(?:a|abbr|acronym ..." at ARGS:wp_post.
The rule ID of the matched rule:
[id "941320"]
The additional matching data from the rule, which explains precisely what caused the rule match:
[data "Matched Data: <h1> found within ARGS:wp_post: <h1>welcome to my blog</h1>"]
Tip
CRS ships with a prebuilt rule exclusion package for WordPress, as well as other popular web applications, to help prevent false positives. See the section on rule exclusion packages for details.
Why are False Positives a Problem?
Alert Fatigue
If a system is prone to reporting false positives then the alerts it raises may be ignored. This may lead to real attacks being overlooked. For this reason, leaving false positives mixed in with real attacks is dangerous: the false positives should be resolved.
Sensitive Information and Regulatory Compliance
A false positive alert may contain sensitive information, for example usernames, passwords, and payment card data. Imagine a situation where a web application user has set their password to ‘/bin/bash’: without proper tuning, this input would cause a false positive every time the user logged in, writing the user’s password to the error log file in plaintext as part of the alert.
It’s also important to consider issues surrounding regulatory compliance. Data protection and privacy laws, like GDPR and CCPA, place strict duties and limitations on what information can be gathered and how that information is processed and stored. The unnecessary logging data generated by false positives can cause problems in this regard.
Poor User Experience
When working in strict blocking mode, false positives can cause legitimate user transactions to be blocked, leading to poor user experience. This can create pressure to disable the CRS or even to remove the WAF solution entirely, which is an unnecessary sacrifice of security for usability. The correct solution to this problem is to tune away the false positives so that they don’t reoccur in the future.
Tuning Away False Positives
Directly Modifying CRS Rules
Warning
Making direct modifications to CRS rule files is a bad idea and is strongly discouraged.
It may seem logical to prevent false positives by modifying the offending CRS rules. If a detection pattern in a CRS rule is causing matches with genuine transactions then the pattern could be modified. This is a bad idea.
Directly modifying CRS rules essentially creates a fork of the rule set. Any modifications made would be undone by a rule set update, meaning that any changes would need to be continually reapplied by hand. This is a tedious, time consuming, and error-prone solution.
There are alternative ways to deal with false positives, as described below. These methods sometimes require slightly more effort and knowledge but they do not cause problems when performing rule set updates.
Rule Exclusions
Overview
The ModSecurity WAF engine has flexible ways to tune away false positives. It provides several rule exclusion (RE) mechanisms which allow rules to be modified without directly changing the rules themselves. This makes it possible to work with third-party rule sets, like CRS, by adapting rules as needed while leaving the rule set files intact and unmodified. This allows for easy rule set updates.
Two fundamentally different types of rule exclusions are supported:
Configure-time rule exclusions: Rule exclusions that are applied once, at configure-time (e.g. when (re)starting or reloading ModSecurity, or the server process that holds it). For example: “remove rule X at startup and never execute it.”
This type of rule exclusion takes the form of a ModSecurity directive, e.g. SecRuleRemoveById.
Runtime rule exclusions: Rule exclusions that are applied at runtime on a per-transaction basis (e.g. exclusions that can be conditionally applied to some transactions but not others). For example: “if a transaction is a POST request to the location ’login.php’, remove rule X.”
This type of rule exclusion takes the form of a SecRule.
Info
Runtime rule exclusions, while granular and flexible, have a computational overhead, albeit a small one. A runtime rule exclusion is an extra SecRule which must be evaluated for every transaction.
In addition to the two types of exclusions, rules can be excluded in two different ways:
Exclude the entire rule/tag: An entire rule, or entire category of rules (by specifying a tag), is removed and will not be executed by the rule engine.
Exclude a specific variable from the rule/tag: A specific variable will be excluded from a specific rule, or excluded from a category of rules (by specifying a tag).
These two methods can also operate on multiple individual rules, or even entire rule categories (identified either by tag or by using a range of rule IDs).
The combinations of rule exclusion types and methods allow for writing rule exclusions of varying granularity. Very coarse rule exclusions can be written, for example “remove all SQL injection rules” using SecRuleRemoveByTag. Extremely granular rule exclusions can also be written, for example “for transactions to the location ‘web_app_2/function.php’, exclude the query string parameter ‘user_id’ from rule 920280” using a SecRule and the action ctl:ruleRemoveTargetById.
The different rule exclusion types and methods are summarized in the table below, which presents the main ModSecurity directives and actions that can be used for each type and method of rule exclusion:
Exclude entire rule/tag
Exclude specific variable from rule/tag
Configure-time
SecRuleRemoveById* SecRuleRemoveByTag
SecRuleUpdateTargetByIdSecRuleUpdateTargetByTag
Runtime
ctl:ruleRemoveById** ctl:ruleRemoveByTag
ctl:ruleRemoveTargetByIdctl:ruleRemoveTargetByTag
*Can also exclude ranges of rules or multiple space separated rules.
**Can also exclude ranges of rules (not currently supported in ModSecurity v3).
Tip
This table is available as a well presented, downloadable Rule Exclusion Cheatsheet from Christian Folini.
Note
When using SecRuleUpdateTargetById and ctl:ruleRemoveTargetById with chained rules, target exclusions are only applied to the first rule in the chain. You can’t exclude targets from other rules in the chain, depending on how the rule is written, you may have to remove the entire rule using SecRuleRemoveById or ctl:ruleRemoveById. This is a current limitation of the SecLang configuration language.
Note
There’s also a third group of rule exclusion directives and actions, the use of which is discouraged. As well as excluding rules “ById” and “ByTag”, it’s also possible to exclude “ByMsg” (SecRuleRemoveByMsg, SecRuleUpdateTargetByMsg, ctl:ruleRemoveByMsg, and ctl:ruleRemoveTargetByMsg). This excludes rules based on the message they write to the error log. These messages can be dynamic and may contain special characters. As such, trying to exclude rules by message is difficult and error-prone.
CRS rules typically feature multiple tags, grouping them into different categories. For example, a rule might be tagged by attack type (‘attack-rce’, ‘attack-xss’, etc.), by language (’language-java’, ’language-php’, etc.), and by platform (‘platform-apache’, ‘platform-unix’, etc.).
Tags can be used to remove or modify entire categories of rules all at once, but some tags are more useful than others in this regard. Tags for specific attack types, languages, and platforms may be useful for writing rule exclusions. For example, if lots of the SQL injection rules are causing false positives but SQL isn’t in use anywhere in the back end web application then it may be worthwhile to remove all CRS rules tagged with ‘attack-sqli’ (SecRuleRemoveByTag attack-sqli).
Some rule tags are not useful for rule exclusion purposes. For example, there are generic tags like ’language-multi’ and ‘platform-multi’: these contain hundreds of rules across the entire CRS, and they don’t represent a meaningful rule property to be useful in rule exclusions. There are also tags that categorize rules based on well known security standards, like CAPEC and PCI DSS (e.g. ‘capec/1000/153/267’, ‘PCI/6.5.4’). These tags may be useful for informational and reporting purposes but are not useful in the context of writing rule exclusions.
Excluding rules using tags may be more useful than excluding using rule ranges in situations where a category of rules is spread across multiple files. For example, the ’language-php’ rules are spread across several different rule files (both inbound and outbound rule files).
Rule Ranges
As well as rules being tagged using different categories, CRS rules are organized into files by general category. In addition, CRS rule IDs follow a consistent numbering convention. This makes it easy to remove unwanted types of rules by removing ranges of rule IDs. For example, the file REQUEST-913-SCANNER-DETECTION.conf contains rules related to detecting well known scanners and crawlers, which all have rule IDs in the range 913000-913999. All of the rules in this file can be easily removed using a configure-time rule exclusion, like so:
SecRuleRemoveById "913000-913999"
Excluding rules using rule ranges may be more useful than excluding using tags in situations where tags are less relevant or where tags vary across the rules in question. For example, a rule range may be the most appropriate solution if the goal is to remove all rules contained in a single file, regardless of how the rules are tagged.
Support for Regular Expressions
Most of the configure-time rule exclusion directives feature some level of support for using regular expressions. This makes it possible, for example, to exclude a dynamically named variable from a rule. The directives with support for regular expressions are:
SecRuleRemoveByTag
A regular expression is used for the tag match. For example, SecRuleRemoveByTag "injection" would match both “attack-injection-generic” and “attack-injection-php”.
SecRuleRemoveByMsg
A regular expression is used for the message match. For example, SecRuleRemoveByMsg "File Access" would match both “OS File Access Attempt” and “Restricted File Access Attempt”.
A regular expression can optionally be used in the target specification by enclosing the regular expression in forward slashes. This is useful for dealing with dynamically named variables, like so:
This example would exclude request cookies named “uid_0123456”, “uid_6543210”, etc. from rule 942440.
Note
The ‘ctl’ action for writing runtime rule exclusions does not support any use of regular expressions. This is a known limitation of the ModSecurity rule engine.
Placement of Rule Exclusions
It is crucial to put rule exclusions in the correct place, otherwise they may not work.
Configure-time rule exclusions: These must be placed after the CRS has been included in a configuration. For example:
# Include CRSInclude crs/rules/*.conf
# Configure-time rule exclusions...
Configure-time rule exclusions remove rules. A rule must already be defined before it can be removed (something cannot be removed if it doesn’t yet exist). As such, this type of rule exclusion must appear after the CRS and all its rules have been included.
Runtime rule exclusions: These must be placed before the CRS has been included in a configuration. For example:
# Runtime rule exclusions...
# Include CRSInclude crs/rules/*.conf
Runtime rule exclusions modify rules in some way. If a rule is to be modified then this should occur before the rule is executed (modifying a rule after it has been executed has no effect). As such, this type of rule exclusion must appear before the CRS and all its rules have been included.
Tip
CRS ships with the files REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf.example and RESPONSE-999-EXCLUSION-RULES-AFTER-CRS.conf.example. After dropping the “.example” suffix, these files can be used to house “BEFORE-CRS” (i.e. runtime) and “AFTER-CRS” (i.e. configure-time) rule exclusions in their correct places relative to the CRS rules. These files also contain example rule exclusions to copy and learn from.
Example 1 (SecRuleRemoveById)
(Configure-time RE. Exclude entire rule.)
Scenario: Rule 933151, “PHP Injection Attack: Medium-Risk PHP Function Name Found”, is causing false positives. The web application behind the WAF makes no use of PHP. As such, it is deemed safe to tune away this false positive by completely removing rule 933151.
Rule Exclusion:
# CRS Rule Exclusion: 933151 - PHP Injection Attack: Medium-Risk PHP Function Name FoundSecRuleRemoveById 933151
Example 2 (SecRuleRemoveByTag)
(Configure-time RE. Exclude entire tag.)
Scenario: Several different parts of a web application are causing false positives with various SQL injection rules. None of the web services behind the WAF make use of SQL, so it is deemed safe to tune away these false positives by removing all the SQLi detection rules.
Rule Exclusion:
# CRS Rule Exclusion: Remove all SQLi detection rulesSecRuleRemoveByTag attack-sqli
Example 3 (SecRuleUpdateTargetById)
(Configure-time RE. Exclude specific variable from rule.)
Scenario: The content of a POST body parameter named ‘wp_post’ is causing false positives with rule 941320, “Possible XSS Attack Detected - HTML Tag Handler”. Removing this rule entirely is deemed to be unacceptable: the rule is not causing any other issues, and the protection it provides should be retained for everything apart from ‘wp_post’. It is decided to tune away this false positive by excluding ‘wp_post’ from rule 941320.
Rule Exclusion:
# CRS Rule Exclusion: 941320 - Possible XSS Attack Detected - HTML Tag HandlerSecRuleUpdateTargetById 941320"!ARGS:wp_post"
Example 4 (SecRuleUpdateTargetByTag)
(Configure-time RE. Exclude specific variable from rule.)
Scenario: The values of request cookies with random names of the form ‘uid_<STRING>’ are causing false positives with various SQL injection rules. It is decided that it is not a risk to allow SQL-like content in cookie values, however it is deemed unacceptable to disable the SQLi detection rules for anything apart from the request cookies in question. It is decided to tune away these false positives by excluding only the problematic request cookies from the SQLi detection rules. A regular expression is to be used to handle the random string portion of the cookie names.
Rule Exclusion:
# CRS Rule Exclusion: Exclude the request cookies 'uid_<STRING>' from the SQLi detection rulesSecRuleUpdateTargetByTag attack-sqli "!REQUEST_COOKIES:/^uid_.*/"
Example 5 (ctl:ruleRemoveById)
(Runtime RE. Exclude entire rule.)
Scenario: Rule 920230, “Multiple URL Encoding Detected”, is causing false positives at the specific location ‘/webapp/function.php’. This is being caused by a known quirk in how the web application has been written, and it cannot be fixed in the application. It is deemed safe to tune away this false positive by removing rule 920230 for that specific location only.
Scenario: Several different locations under ‘/web_app_1/content’ are causing false positives with various SQL injection rules. Nothing under that location makes any use of SQL, so it is deemed safe to remove all the SQLi detection rules for that location. Other locations may make use of SQL, however, so the SQLi detection rules must remain in place everywhere else. It has been decided to tune away the false positives by removing all the SQLi detection rules for locations under ‘/web_app_1/content’ only.
(Runtime RE. Exclude specific variable from rule.)
Scenario: The content of a POST body parameter named ’text_input’ is causing false positives with rule 941150, “XSS Filter - Category 5: Disallowed HTML Attributes”, at the specific location ‘/dynamic/new_post’. Removing this rule entirely is deemed to be unacceptable: the rule is not causing any other issues, and the protection it provides should be retained for everything apart from ’text_input’ at the specific problematic location. It is decided to tune away this false positive by excluding ’text_input’ from rule 941150 for location ‘/dynamic/new_post’ only.
(Runtime RE. Exclude specific variable from rule.)
Scenario: The values of request cookie ‘uid’ are causing false positives with various SQL injection rules when trying to log in to a web service at location ‘/webapp/login.html’. It is decided that it is not a risk to allow SQL-like content in this specific cookie’s values for the login page, however it is deemed unacceptable to disable the SQLi detection rules for anything apart from the specific request cookie in question at the login page only. It is decided to tune away these false positives by excluding only the problematic request cookie from the SQLi detection rules, and only when accessing ‘/webapp/login.html’.
Rule Exclusion:
# CRS Rule Exclusion: Exclude the request cookie 'uid' from the SQLi detection rulesSecRule REQUEST_URI "@beginsWith /webapp/login.html" \
"id:1030,\
phase:1,\
pass,\
t:none,\
nolog,\
ctl:ruleRemoveTargetByTag=attack-sqli;REQUEST_COOKIES:uid"
Example 9 Content Type
(Runtime RE. Selectively allowing Content Type.)
Scenario: A POST request with a Content Type of text/plain is being sent to /webapp/login.html, this request is blocked because text/plain is not in the list of allowed Content Types for rule 920420. CRS only allows Content Types it knows the WAF can safely parse. It is decided to allow the text/plain Content Type only for /webapp/login.html and to enable the approate body parser, which is JSON for this example. A chain rule it utilized to ensure the JSON body processor is only switched on for the text/plain Content Type.
Rule Exclusion:
# CRS Rule Exclusion: Allow text/plain Content Type and switch on JSON body processorSecRule REQUEST_URI "@beginsWith /webapp/login.html" \
"id:1040,\
phase:1,\
pass,\
t:none,\
nolog,\
chain"
SecRule REQUEST_HEADERS:Content-Type "@beginsWith text/plain" \
"t:none,\
ctl:requestBodyProcessor=JSON,\
setvar:'tx.allowed_request_content_type=%{tx.allowed_request_content_type} |text/plain|'"
Warning
ModSecurity/Coraza relies on the Content Type to correctly parse a request body, allowing additional Content Types may result in a complete WAF bypass if the correct body parser has not been activated. The example provided here should be safe.
Tip
It’s possible to write a conditional rule exclusion that tests something other than just the request URI. Conditions can be built which test, for example, the source IP address, HTTP request method, HTTP headers, and even the day of the week.
Multiple conditions can also be chained together to create a logical AND by using ModSecurity’s chain action. This allows for creating powerful rule logic like “for transactions that are from source IP address 10.0.0.1 AND that are for location ‘/login.html’, exclude the query string parameter ‘user_id’ from rule 920280”. Extremely granular and specific rule exclusions can be written, in this way.
Rule Exclusion Packages
CRS ships with prebuilt rule exclusion packages for a selection of popular web applications. These packages contain application-specific rule exclusions designed to prevent false positives from occurring when CRS is put in front of one of these web applications.
The packages should be viewed as a good starting point from which to build upon. Some false positives may still occur, for example if working at a high paranoia level, if using a very new or old version of the application, if using plug-ins, add-ons, or user customizations.
If using a native CRS installation, rule exclusion packages can be enabled in the file crs-setup.conf. Modify rule 900130 to select the web applications in question, e.g. to enable the DokuWiki rule exclusion package use setvar:tx.crs_exclusions_dokuwiki=1, and then uncomment the rule to enable it.
If running CRS where it has been integrated into a commercial product or CDN then support varies. Some vendors expose rule exclusion packages in the GUI while other vendors require custom rules to be written which set the necessary variables. Unfortunately, there are also vendors that don’t allow rule exclusion packages to be used at all.
Tip
If running multiple web applications, it is highly recommended to enable a rule exclusion package only for the location where the corresponding web application resides. For example, to enable the WordPress rule exclusion package only for locations under ‘/wordpress’, a rule like the following could be used:
SecRule REQUEST_URI "@beginsWith /wordpress/" setvar:tx.crs_exclusions_wordpress=1...
Or if CRS is running on an reverse-proxy with multiple apps, you can enable plugins per domain using either [SecWebAppID](https://github.com/owasp-modsecurity/ModSecurity/wiki/Reference-Manual-(v2.x)#user-content-SecWebAppId) (Unsupported on Coraza):
```apache
SecRule WebAppID "@streq wordpress" setvar:tx.crs_exclusions_wordpress=1...
The CRS project is always looking to work with other communities and individuals to add support for additional web applications. Please get in touch via GitHub to discuss writing a rule exclusion package for a specific web application.
Sampling mode makes it possible to apply CRS to a limited percentage of traffic only. This may be useful in certain scenarios when enabling CRS for the first time, as this page explains.
Introduction to Sampling Mode
The CRS’s sampling mode mechanism was first introduced in version 3.0.0 in 2016. Although the feature has been available since then, it’s rarely used in practice, partly due to it being one of the lesser-known features of CRS.
When deploying ModSecurity and CRS in front of an existing web service for the first time, it’s difficult to predict what’s going to happen when CRS is turned on. A well-developed test environment can help, but it’s rare to find an installation where real world traffic can be reproduced 1:1 on a test setup. As such, fully enabling ModSecurity and CRS can be something of a leap into the unknown, and potentially very disruptive. This scenario prompted the introduction of CRS 3’s sampling mode.
Sampling mode makes it possible to run CRS on a limited percentage of traffic. The remaining traffic will bypass the rule set. If it turns out that ModSecurity is extremely disruptive or if the rules are too resource heavy for the server, only a limited percentage of the total traffic can be negatively affected (for example, only 1%). This significantly reduces the potential impact and risk of enabling CRS, especially when the logs are being monitored and the deployment can be rolled back if the alerts start to pile up.
Using sampling mode means that CRS offers relatively little security if the sampling percentage is set to be low. The idea, however, is to increase the percentage over time, from 1% to 2%, to 5%, 10%, 20%, 50%, and ultimately to 100%, where the rules are applied to all traffic.
The default sampling percentage of CRS is 100%. As such, if sampling is not of interest then the option can be safely ignored.
Applying Sampling Mode
Sampling mode is controlled by setting the sampling percentage. This is defined in the crs-setup.conf configuration file and can be found in the rule with ID 900400. To use sampling mode, uncomment this rule and set the variable tx.sampling_percentage to the desired value:
To test sampling mode, set the sampling percentage to 50 (which represents 50%), reload the server, and issue a few requests featuring a payload resembling an exploit. For example:
If CRS is applied to the transaction (and the inbound anomaly threshold is set to 10 or lower) then a 403 Forbidden status code will be returned, since the request causes two critical rules to match, by default.
If sampling mode is triggered for the transaction (with a 50% probability) then the rule set will be bypassed and an ordinary response will be received, e.g. a 200 OK status code.
In the latter case, where sampling mode is triggered and CRS is bypassed, an alert like the following can be found in the error log:
[Wed Jan 01 00:00:00.123456 2022] [:error] [pid 3728:tid 139664291870464] [client 10.0.0.1:0] [client 10.0.0.1] ModSecurity: Warning. Match of "lt %{tx.sampling_percentage}" against "TX:sampling_rnd100" required. [file "/etc/crs/rules/REQUEST-901-INITIALIZATION.conf"] [line "434"] [id "901450"] [msg "Sampling: Disable the rule engine based on sampling_percentage 50 and random number 81"] [ver "OWASP_CRS/3.3.2"] [hostname "www.example.com"] [uri "/index.html"] [unique_id "YgBKx4BqNoKe-XoGhPCPtAAAAIQ"]
Here, CRS reports that it disabled the rule engine because the random number was above the sampling limit. The sampling percentage is set at the desired level, the rule set generates a random integer in the range 0-99 per-transaction, and if it’s above the sampling percentage then the WAF is disabled for the remainder of the transaction.
Warning
As sampling mode works by selectively disabling the ModSecurity WAF engine, if other rule sets are installed then they will be bypassed too.
For requests where the rule set is bypassed, a log entry is emitted by rule 901450.
For the other requests, those without a corresponding 901450 entry, the rule set is applied normally.
Disabling Sampling Mode Log Entries
If the log entires generated by rule 901450 seem excessive in volume then the rule can be silenced by applying the following directive, either after the CRS include statement or in the file RESPONSE-999-EXCLUSION-RULES-AFTER-CRS.conf:
SecRuleUpdateActionById 901450"nolog"
Rollback
If CRS is deployed in front of a large service and sampling mode is in use, with a low sampling rate defined, if the logs still start piling up then it may be desirable to completely disable CRS. Rather than carrying out a full rollback of the deployment, the quickest solution is to define tx.sampling_percentage to be 0, which means that every request will bypass the WAF (a sampling percentage of 0%: “sample 0% of traffic”). This will take effect once the web server has been reloaded so that it picks up the modified configuration. This leaves ModSecurity and CRS installed and ready for use, but completely disabled.
Random Number Generation
ModSecurity has no built-in functionality to return random numbers, forcing CRS to find entropy for itself. It does this by taking advantage of the fact that the UNIQUE_ID variable, which identifies each request with a token that’s guaranteed to be unique, has a random element to it. This is the entropy that’s used for sampling.
Rule 901410 hashes the unique ID and encodes the result as a string of hexadecimal characters. The first two digits of the string are then extracted to get a random number from 0 to 99. In the extremely rare case where the hex encoded hash doesn’t contain a digit, there’s a fallback routine in place which takes the last digits of the DURATION variable.
The random numbers generated using this method are not cryptographically secure, but they are sufficient for the purposes of sampling.
About Rules
Rules
Subsections of About Rules
Rule IDs
Note
The content on this page may be outdated. We are currently in the process of rewriting all of our documentation: please bear with us while we update our older content.
Why do rule IDs matter?
Each rule added to a ModSecurity instance must have a unique ID (in
recent versions of modsec). As a result of this it is important that IDs
be generated in a preplanned way such that they don't overlap with
other rules. This becomes particularly important when it comes to
rulesets, like OWASP CRS. Because CRS can be used with other rule sets
(in fact it is designed to be used with the Trustwave commercial rules,
for instance) it is important that no two rulesets have overlapping ID
ranges. To aid in this process the project maintains a list of reserved
ID spaces. If you are planning on publishing rules or a ruleset please
reach out to security[ at ]modsecurity.org and we can reserve a range
of IDs for you thank you.
ID Reservations
ID Range
Reserved for
1-99,999
reserved for local (internal) use. Use as you see fit but do not use this range for rules that are distributed to others.
ID’s within the OWASP CRS (CRS) have special meaning. Rules
are assigned an ID based on their location within the ruleset. As the
list above notes, OWASP CRS is assigned ID’s from 900,000
to 999,999. This means that each rule file in CRS 3.x has 1000 IDs
reserved for it. Currently, this is more than enough space, however, if
at some point this becomes a problem we’ll cross that bridge when we
come to it. By design rules will always be separated by 10 IDs from the
ID before it. The first 10 ID’s (000
010,020,030,040,050,060,070,080,090) are designated for control flow
related rules, that is typically rules that will trigger a skip action
(these will be at the beginning of a file or rules that pass). As a
result of this structure most rule files will start with ID
9[File_ID]100. As new rules are developed they should be added at the
end. If it becomes necessary to add a rule in-between existing rules
this must be noted in the comments.
Mapping 3.0.0-dev(2.x) IDs to 3.0.0-rc1 IDs
When we started developing CRS 3 we started with our old ModSecurity 2.x
rules and used our experience to redesign the layout of the ruleset,
refine rules that were failing, and add new controls that were needed.
As a result of this in pre-release version of 3.x we ran into problems
where rule IDs were all of the place. Not only was this confusing but it
restricted the ability to do range based ID exclusions easily. As a
result we re-structured the rule ID's to what we see above.
However, this is problematic for people who have made exceptions based
on these existing rules. For these people we provide the following
table:
You can use the above file along with a script similar to the one below
to update exclusions or rule changes:
#!/usr/bin/env python3# -*- coding: utf-8 -*-import csv
import argparse
import os
import sys
idTranslationFile ="IdNumbering.csv"if(not os.path.isfile(idTranslationFile)):
sys.stderr.write("We were unable to locate the ID translation CSV (idNumbering.csv) please place this is the same directory as this script\n")
sys.exit(1)
parser = argparse.ArgumentParser(description="A program that takes in an exceptions file and renumbers all the ID to match OWASP CRS 3.0-rc1 numbers. Output will be directed to STDOUT and can be used to overwrite the file using '>'")
parser.add_argument("-f", "--file", required=True, action="store", dest="fname", help="the file to be renumbered")
args = parser.parse_args()
if(not os.path.isfile((args.fname).encode('utf8'))):
sys.stderr.write("We were unable to find the file you were trying to upate the ID numbers in, please check your path\n")
sys.exit(1)
fcontent =""try:
f = open((args.fname).encode('utf-8'), "r")
try:
fcontent = f.read()
finally:
f.close()
exceptIOError:
sys.stderr.write("There was an error opening the file you were trying to update")
if(fcontent !=""):
# CSV File f = open(idTranslationFile, 'rt')
try:
reader = csv.reader(f)
for row in reader:
fcontent.replace(row[0], row[1])
finally:
f.close()
print fcontent
This file is used to add LOCAL exceptions for your site. Often in this file we would see rules that short-circuit inspection and allow certain transactions to skip through inspection.
REQUEST-901-INITIALIZATION.conf
This file initializes the Core Rules and performs preparatory actions. It also fixes errors and omissions of variable definitions in the crs-setup.conf file. The crs-setup.conf can and should be edited by the user, but this file is part of the CRS installation and should not be altered.
REQUEST-905-COMMON-EXCEPTIONS.conf
This file is used as an exception mechanism to remove common false positives that may be encountered. It includes exceptions for Apache SSL pinger, Apache internal dummy connections, and other legitimate traffic that should bypass CRS inspection.
REQUEST-911-METHOD-ENFORCEMENT.conf
These rules enforce the configured allowed HTTP methods policy. Requests using HTTP methods not explicitly permitted in the configuration (defined in tx.allowed_methods) will be blocked to prevent potential attacks using uncommon or dangerous HTTP methods.
REQUEST-913-SCANNER-DETECTION.conf
These rules are concentrated around detecting security tools and scanners.
REQUEST-920-PROTOCOL-ENFORCEMENT.conf
The rules in this file center around detecting requests that either violate HTTP or represent a request that no modern browser would generate, for instance missing a user-agent.
REQUEST-921-PROTOCOL-ATTACK.conf
The rules in this file focus on specific attacks against the HTTP protocol itself such as HTTP Request Smuggling and Response Splitting.
REQUEST-922-MULTIPART-ATTACK.conf
These rules protect against multipart-related attacks and address the 3UWMWA6W vulnerability. They enforce strict policies on multipart content, including charset definitions and content-type headers. Requires ModSecurity version 2.9.6 or newer, or 3.0.8 or newer.
REQUEST-930-APPLICATION-ATTACK-LFI.conf
These rules attempt to detect when a user is trying to include a file that would be local to the webserver that they should not have access to. Exploiting this type of attack can lead to the web application or server being compromised.
REQUEST-931-APPLICATION-ATTACK-RFI.conf
These rules attempt to detect when a user is trying to include a remote resource into the web application that will be executed. Exploiting this type of attack can lead to the web application or server being compromised.
REQUEST-932-APPLICATION-ATTACK-RCE.conf
These rules detect Unix and Windows command injection attacks. Command injections occur when an application executes shell commands without proper input escaping or validation. Attackers can exploit this by inserting command separators and additional commands into user input. This file also protects against Oracle WebLogic Remote Command Execution exploits.
REQUEST-933-APPLICATION-ATTACK-PHP.conf
These rules provide protection against PHP injection attacks. The rules detect PHP open tags (such as “<?php” and “<?”), PHP functions commonly used in exploits, and various PHP-based attack patterns that could lead to remote code execution or application compromise.
REQUEST-934-APPLICATION-ATTACK-GENERIC.conf
These rules detect generic application attacks including NodeJS insecure deserialization vulnerabilities and generic Remote Code Execution (RCE) signatures. This includes patterns like eval(), function constructors, String.fromCharCode(), and insecure deserialization markers used by node-serialize and funcster libraries.
REQUEST-941-APPLICATION-ATTACK-XSS.conf
These rules provide protection against Cross-Site Scripting (XSS) attacks by detecting malicious scripts, HTML tags, and JavaScript code in user input. The rules also detect path-based XSS exploits and include performance optimizations to minimize false positives while maintaining strong protection.
REQUEST-942-APPLICATION-ATTACK-SQLI.conf
Within this configuration file we provide rules that protect against SQL injection attacks. SQLi attackers occur when an attacker passes crafted control characters to parameters to an area of the application that is expecting only data. The application will then pass the control characters to the database. This will end up changing the meaning of the expected SQL query.
These rules focus around providing protection against Session Fixation attacks.
REQUEST-944-APPLICATION-ATTACK-JAVA.conf
These rules detect Java-based attacks including Remote Command Execution exploits targeting Java classes. The rules provide protection against Apache Struts vulnerabilities (CVE-2017-5638, CVE-2017-9791, CVE-2017-9805) and Oracle WebLogic Remote Command Execution exploits (CVE-2017-10271).
REQUEST-949-BLOCKING-EVALUATION.conf
These rules provide the anomaly based blocking for a given request. If you are in anomaly detection mode this file must not be deleted.
REQUEST-999-COMMON-EXCEPTIONS-AFTER.conf
This file contains common exception rules that remove false positives for well-known applications and services, such as Google Analytics cookies, Google Ads cookies, and other legitimate third-party services. This file must be loaded after all the request rules have been created.
RESPONSE-950-DATA-LEAKAGES.conf
These rules provide protection against data leakages that may occur genericly
RESPONSE-951-DATA-LEAKAGES-SQL.conf
These rules provide protection against data leakages that may occur from backend SQL servers. Often these are indicative of SQL injection issues being present.
RESPONSE-952-DATA-LEAKAGES-JAVA.conf
These rules provide protection against data leakages that may occur because of Java
RESPONSE-953-DATA-LEAKAGES-PHP.conf
These rules provide protection against data leakages that may occur because of PHP
RESPONSE-954-DATA-LEAKAGES-IIS.conf
These rules provide protection against data leakages that may occur because of Microsoft IIS.
RESPONSE-955-WEB-SHELLS.conf
These rules provide detection and blocking of web shells in response bodies. Web shells are malicious scripts uploaded to web servers that provide attackers with remote command execution capabilities. The rules detect PHP, JSP, ASP, and other types of web shells that may indicate a successful server compromise.
RESPONSE-956-DATA-LEAKAGES-RUBY.conf
These rules provide protection against data leakages that may occur from Ruby applications. The rules detect Ruby error messages and stack traces in response bodies that could reveal sensitive information about the application’s internal structure.
RESPONSE-959-BLOCKING-EVALUATION.conf
These rules provide the anomaly based blocking for a given response. If you are in anomaly detection mode this file must not be deleted.
RESPONSE-980-CORRELATION.conf
The rules in this configuration file facilitate the gathering of data about successful and unsuccessful attacks on the server.
This file is used to add LOCAL exceptions for your site. Often in this file we would see rules that short-circuit inspection and allow certain transactions to skip through inspection.
This file is used to add LOCAL exceptions for your site. Often in this file we would see rules that short-circuit inspection and allow certain transactions to skip through inspection.
REQUEST-901-INITIALIZATION.conf
This file initializes the Core Rules and performs preparatory actions. It also fixes errors and omissions of variable definitions in the crs-setup.conf file. The crs-setup.conf can and should be edited by the user, but this file is part of the CRS installation and should not be altered.
REQUEST-903.9001-DRUPAL-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default Drupal installation. They disable CRS checks on well-known parameter fields that often trigger false alarms, including session cookies, password fields, and article/node bodies. The exclusions are only active if crs_exclusions_drupal=1 is set in crs-setup.conf.
REQUEST-903.9002-WORDPRESS-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default WordPress installation. They provide exceptions for WordPress login forms, admin panels, and other WordPress-specific functionality. The exclusions are only active if crs_exclusions_wordpress=1 is set in crs-setup.conf. Note that WordPress comment fields are NOT excluded from checking due to security concerns.
REQUEST-903.9003-NEXTCLOUD-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default NextCloud installation. They likely work with OwnCloud as well. The rules provide exceptions for file uploads, WebDAV operations, and other NextCloud-specific functionality. The exclusions are only active if crs_exclusions_nextcloud=1 is set in crs-setup.conf.
REQUEST-903.9004-DOKUWIKI-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default DokuWiki installation. They provide exceptions for wiki page editing, autosave functionality, and file uploads. The exclusions are only active if crs_exclusions_dokuwiki=1 is set in crs-setup.conf.
REQUEST-903.9005-CPANEL-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default cPanel environment. They provide exceptions for cPanel WHM server status requests and other cPanel-specific functionality. The exclusions are only active if crs_exclusions_cpanel=1 is set in crs-setup.conf.
REQUEST-903.9006-XENFORO-EXCLUSION-RULES.conf
These exclusion rules remedy false positives in a default XenForo forum installation. They provide exceptions for forum posts, image proxies, and other XenForo-specific functionality. The exclusions are only active if crs_exclusions_xenforo=1 is set in crs-setup.conf.
REQUEST-910-IP-REPUTATION.conf
These rules detect and block traffic from IP addresses that have previously been involved with malicious activity based on traffic violations detected in previous requests. When a client IP is flagged, subsequent requests from that IP are blocked during a timeout period.
REQUEST-912-DOS-PROTECTION.conf
These anti-automation rules detect application layer (Layer 7) Denial of Service attacks. The rules track request rates per IP address and identify burst patterns. When an IP exceeds the configured thresholds, it is temporarily blocked. The DoS counter tracks requests to non-static resources and raises blocking flags when limits are exceeded.
REQUEST-913-SCANNER-DETECTION.conf
These rules are concentrated around detecting security tools and scanners.
REQUEST-920-PROTOCOL-ENFORCEMENT.conf
The rules in this file center around detecting requests that either violate HTTP or represent a request that no modern browser would generate, for instance missing a user-agent.
REQUEST-921-PROTOCOL-ATTACK.conf
The rules in this file focus on specific attacks against the HTTP protocol itself such as HTTP Request Smuggling and Response Splitting.
REQUEST-930-APPLICATION-ATTACK-LFI.conf
These rules attempt to detect when a user is trying to include a file that would be local to the webserver that they should not have access to. Exploiting this type of attack can lead to the web application or server being compromised.
REQUEST-931-APPLICATION-ATTACK-RFI.conf
These rules attempt to detect when a user is trying to include a remote resource into the web application that will be executed. Exploiting this type of attack can lead to the web application or server being compromised.
REQUEST-932-APPLICATION-ATTACK-RCE.conf
These rules detect Unix and Windows command injection attacks. Command injections occur when an application executes shell commands without proper input escaping or validation. Attackers can exploit this by inserting command separators and additional commands into user input. This file also protects against Oracle WebLogic Remote Command Execution exploits.
REQUEST-933-APPLICATION-ATTACK-PHP.conf
These rules provide protection against PHP injection attacks. The rules detect PHP open tags (such as “<?php” and “<?”), PHP functions commonly used in exploits, and various PHP-based attack patterns that could lead to remote code execution or application compromise.
REQUEST-934-APPLICATION-ATTACK-GENERIC.conf
These rules detect generic application attacks including NodeJS insecure deserialization vulnerabilities and generic Remote Code Execution (RCE) signatures. This includes patterns like eval(), function constructors, String.fromCharCode(), and insecure deserialization markers used by node-serialize and funcster libraries.
REQUEST-941-APPLICATION-ATTACK-XSS.conf
These rules provide protection against Cross-Site Scripting (XSS) attacks by detecting malicious scripts, HTML tags, and JavaScript code in user input. The rules also detect path-based XSS exploits and include performance optimizations to minimize false positives while maintaining strong protection.
REQUEST-942-APPLICATION-ATTACK-SQLI.conf
Within this configuration file we provide rules that protect against SQL injection attacks. SQLi attackers occur when an attacker passes crafted control characters to parameters to an area of the application that is expecting only data. The application will then pass the control characters to the database. This will end up changing the meaning of the expected SQL query.
These rules focus around providing protection against Session Fixation attacks.
REQUEST-944-APPLICATION-ATTACK-JAVA.conf
These rules detect Java-based attacks including Remote Command Execution exploits targeting Java classes. The rules provide protection against Apache Struts vulnerabilities (CVE-2017-5638, CVE-2017-9791, CVE-2017-9805) and Oracle WebLogic Remote Command Execution exploits (CVE-2017-10271).
REQUEST-949-BLOCKING-EVALUATION.conf
These rules provide the anomaly based blocking for a given request. If you are in anomaly detection mode this file must not be deleted.
RESPONSE-950-DATA-LEAKAGES.conf
These rules provide protection against data leakages that may occur genericly
RESPONSE-951-DATA-LEAKAGES-SQL.conf
These rules provide protection against data leakages that may occur from backend SQL servers. Often these are indicative of SQL injection issues being present.
RESPONSE-952-DATA-LEAKAGES-JAVA.conf
These rules provide protection against data leakages that may occur because of Java
RESPONSE-953-DATA-LEAKAGES-PHP.conf
These rules provide protection against data leakages that may occur because of PHP
RESPONSE-954-DATA-LEAKAGES-IIS.conf
These rules provide protection against data leakages that may occur because of Microsoft IIS.
RESPONSE-959-BLOCKING-EVALUATION.conf
These rules provide the anomaly based blocking for a given response. If you are in anomaly detection mode this file must not be deleted.
RESPONSE-980-CORRELATION.conf
The rules in this configuration file facilitate the gathering of data about successful and unsuccessful attacks on the server.
This file is used to add LOCAL exceptions for your site. Often in this file we would see rules that short-circuit inspection and allow certain transactions to skip through inspection.
Writing Rules
From years of experience, the CRS project has assembled a wealth of knowledge and advice on how to write clear and efficient WAF rules, as this page outlines.
The CRS project’s advice on rule writing is contained within the contribution guidelines, a document which can also be found in plain text form in CRS releases for offline reference. The guidelines contain invaluable guidance and tips on how to write rules, including:
effective regular expression writing
consistent formatting and indentation
rule action order
CRS paranoia level rule compliance
writing rule tests
While some of the guidelines are specific to writing rules for inclusion in CRS, following the guidelines will help with the creation of any rule set by ensuring that rules are clear, efficient, easy to read, and easy to maintain.
Making Rules
Note
The content on this page may be outdated. We are currently in the process of rewriting all of our documentation: please bear with us while we update our older content.
Making Rules
The Basic Syntax
A SecRule
is a directive like any other understood by ModSecurity. The difference
is that this directive is way more powerful in what it is capable of
representing. Generally, a SecRule is made up of 4 parts:
Variables - Instructs ModSecurity where to look (sometimes called Targets)
Operators - Instructs ModSecurity when to trigger a match
Transformations - Instructs ModSecurity how it should normalize variable data
Actions - Instructs ModSecurity what to do if a rule matches
The preceding rule will take each HTTP Request and obtain just the URI
portion. From there is will transform the URI value to lowercase.
Subsequently it will check to see if that transformed value is equal to
exactly '/index.php'. If it is Modsecurity will deny the request, that
is, it will stop processing further rules and intercept the request.
As can be seen from the previous explaination, one of the unique things
about the SecRule directive is that each SecRule listed in your
configuration is evaluated on each transaction. All the other
ModSecurity directives are only evaluated at startup.
Clearly, if this was all there was to SecRules it wouldn’t be very
powerful. In fact, there is a lot more. So much more that it is in fact
a full fledged language. The best place to find out about all the
possible capabilities is via the ModSecurity Manual.
The following is just a glimpse of its capabilities:
There are ~105 variables in 6 different categories, some examples
include:
While there are a lot of options available there are a few basic things
to remember.
Every SecRule must have a VARIABLE
Every SecRule must have an OPERATOR, if none is listed @rx is
implied.
Every SecRule must have an ACTION. The only required action is id,
however, several actions are implied by SecDefaultAction (default
phase:2,log,auditlog,pass)
Every SecRule must have an phase ACTION, this tells the rule when to
fire. If no phase is included the default is phase:2.
Every SecRule must have a disruptive ACTION. This is an action that
describes what to do with the transaction if triggered. If no
disruptive action is included the default is pass
Transformations are optional but should be used to prevent your rule
from being bypassed
Advanced Variable Usage
Variables themselves are quite easy to access as our earlier rules have
shown. There are a couple of corner cases though. Not all variables are
strings. Some variables, like ARGS_GET are Collections. A
collection is very similar to a dictionary in Python, it is a key value
pair of information. For instance if our request URI was
http://www.example.com?x=test&y=test2 our collection might look like
ARGS_GET = {"x" : "test", "y" : "test2"}. When we request an
VARIABLE that is a collection, ModSecurity will iterate over each value
in the collection, applying transformations and checking against the
operator, until it finds a match. If it finds a match it will stop
processing the rule and undertake any actions specified.
It is possible to access just an index of a collection as well. This
makes addressing specific variable very easy. To do this within the
VARIABLE area of a SecRule you use the ':' (colon).
One operator is nice but what if I have to apply one operator on
multiple rules, for instance I want to check GET parameters and COOKIES.
ModSecurity provides a way for you to do this. You can use the '|'
(pipe) to combine two VARIABLES into one rule. This pipe can be applied
as many times as you want. In the example below we combine both GET and
POST arguments. In fact, this is not necessary in reality as there is a
built in ARGS collections that already does this.
If you are having a problem where one of your variables is causing false
positives or you just don't want to look there you can also remove an
index of a collection using the '!' (exclamation mark). This almost
always used in conjunction with the pipe and an index, ModSecurity will
understand that this means remove this index from the collection
The concept of transformations is very intuitive and thanks to
ModSecurity's open source nature there are quite a few to choose from.
An issue arises in that the proper application of transformations often
takes knowledge about how the threat you are trying to stop can manifest
itself. Imagine the following example - you are trying to detect an XSS
(Cross Site Scripting) attack.
In many contexts HTML entities might be interpreted and converted back
to their ASCII form. That would allow us to by pass this rule with
something like <sCript >alert(1);</script>.
As you can see this type of approach can go on for a while and is why
OWASP CRS is important. We put our rules out there and continuously
allow people to test them. If they find an issue we fix it and the cycle
continues. This attempt to blacklist malicious attacks is a constant
battle, it is always encouraged that you whitelist where available.
Currently if you look at CRS you'll see there are many XSS rules. Each
rule may have 5 or 6 different transformations and the operators get
more complex all the time.
Advanced Action Usage
Advanced Operator Usage
Most OPERATORS are self explanatory. Many operators such as the string
manipulation operators take arguments. Some operators such as the
libinjection @detectXSS do not. In general the semantics for most
OPERATORS is quite straight forward. The exception to this rule is the
default operator @rx, or regular expressions. Even if you know how to
use regular expression, it is still quite easy to make a mistake in a
security context. When writing a rule remember the following guidelines:
Regexp should avoid using ^ (alternative: A) and $
(alternative: Z) symbols, which are metacharacters for start and end
of a string. It is possible to bypass regex by inserting any symbol
in front or after regexp.
Regexp should be case-insensitive. It is possible to bypass regex
using upper or lower cases in words. Modsecurity transformation
commands (which are applied on string before regex pattern is
applied) can also be included in tests to cover more regexps [51].
Regexp should avoid using dot “.” symbol, which means every symbol
except newline (n). It is possible to bypass regex using newline
injection.
Number of repetitions of set or group {} should be carefully used,
as one can bypass such limitation by lowering or increasing
specified numbers.
Best Practice from slides of Ivan Novikov [2]: Modsecurity should
avoid using t:urlDecode function (t:urlDecodeUni instead).
Regexp should only use plus “+” metacharacter in places where it is
necessary, as it means “one or more”. Alternative metacharacter star
“*”, which means “zero or more” is generally preferred.
Usage of wildcards should be reasonable. rn characters can often be
bypassed by either substitution, or by using newline alternative v,
f and others. Wildcard b has different meanings while using wildcard
in square brackets (has meaning “backspace”) and in plain regex (has
meaning “word boundary”), as classified in RegexLib article [42].
Regexp should be applied to right scope of inputs: Cookies names and
values, Argument names and values, Header names and values, Files
argument names and content.
Regular expression writers should be careful while using only
whitespace character (%20) for separating tag attributes. Rule can
be bypassed with newline character: i.e. %0d,%0a.
Greediness of regular expressions should be considered. Highlight of
this topic is well done in Chapter 9 of Jan Goyvaert’s tutorial
[27]. While greediness itself does not create bypasses, bad
implementation of regexp Greediness can raise False Positive rate.
This can cause excessive log-file flooding, forcing vulnerable rule
or even whole WAF to be switched off.
Rules for CRS
All rules for CRS should include at least one regression test. To
increase the chances of having your pull request accepted into the
mainline more regression tests are recommended.
If your rule contains combination of data sources into a single regular
expression for performance reasons you should document the use of the
regexp-assemble command in the comments above your command. You should
also include your independent sources within this util directory. Doing
so increases overall maintainability.
Metadata
Note
The content on this page may be outdated. We are currently in the process of rewriting all of our documentation: please bear with us while we update our older content.
OWASP CRS Metadata
OWASP CRS 3.x includes several pieces of metadata within rules. Not
every rule features all metadata but it is a continuing project where
possible to update this information to the best possible level. If you
see a rule without a piece of metadata that you think is warranted
please open either an issue or a pull
request.
Tags about paranoia level
Starting with version 3 we reintroduced the paranoia level concept.
For tuning purposes we wanted it to be very clear which rules are from
higher paranoia levels. As a result, any rule in a paranoia level
greater than 1 will have a 'paranoia-level' tag. We use a forward
slash to deliminate this tag. Anything after the slash should represent
the paranoia level of that rule. For instance:
tag:'paranoia-level/2'
Tags about rule classification
There are two different types of tags regarding rule classification. One
type of tag carries over from CRS 2.x and one type has been added to CRS
3. The CRS 3 version can be more explanatory and allows for the
capability to use SecRuleRemoveByTag more easily, whereas the CRS 2
versions give information in a more succinct manner and are used for
anomaly scoring purposes.
The CRS 2.x rule classifications are indicated by tags starting with
'OWASP_CRS'. They are delimited by the forward slash (/) and will
always have three parts. The sections get more specific as you progress
through the string where the third section will always be the most
specific. The following are a list of all the current CRS 2.x type tags
that are used in CRS.
The CRS 3.x type tagging is split over a series of tags:
application
language
platform
attack
These tags all have additional information specified after a dash (-).
In some cases, particularly with attack there might be another dash that
represents a more specific variant for instance attack-injection-php. In
general anything after the first dash can be treated as a string. If the
category is general for a given rule the tag will have the data
'multi' an example would be a vulnerability that affects many
different platforms. In this case the tag would look as follows:
tag:'platform-multi'
Additional rule information
Often we will generate rules based on some presentation or article. In
fact, sometimes the construction of the rule is done in such a way that
it might not be naively clear how the rule works. In all of these cases
comments will be left above the rule in question. Items like links will
not appear within tag data.
About Plugins
Subsections of About Plugins
Plugins
The CRS plugin mechanism allows the rule set to be extended in specific, experimental, or unusual ways, as this page explains.
Note
Plugins are not part of the CRS 3.3.x release line. They are released officially with CRS 4.0. In the meantime, plugins can be used with one of the stable releases by following the instructions presented below.
What are Plugins?
Plugins are sets of additional rules that can be plugged in to a web application firewall in order to expand CRS with complementary functionality or to interact with CRS. Rule exclusion plugins are a special case: these are plugins that disable certain rules to integrate CRS in to a context that is otherwise likely to trigger certain false alarms.
Why are Plugins Needed?
Installing only a minimal set of rules is desirable from a security perspective. A term often used is “minimizing the attack window”. For CRS, this means that by having fewer rules, it is less likely to deploy a bug. In the past, CRS had a major bug in one of the rule exclusion packages which affected every standard CRS installation (see CVE-2021-41773). By moving all rule exclusion packages into optional plugins, the risk is reduced in this regard. As such, security is a prime driver for the use of plugins.
A second driver is the need for certain functionality that does not belong in mainline CRS releases. Typical candidates include the following:
ModSecurity features deemed too exotic for mainline, like the use of Lua scripting
New rules that are not yet trusted enough to integrate into the mainline
Specialized functionality with a very limited audience
A plugin might also evolve quicker than the slow release cycle of stable CRS releases. That way, a new and perhaps experimental plugin can be updated quickly.
Finally, there is a need to allow third parties to write plugins that interact with CRS. This was previously very difficult to manage, but with plugins everybody has the opportunity to write anomaly scoring rules.
How do Plugins Work Conceptually?
Plugins are a set of rules. These rules can run in any phase, but in practice it is expected that most of them run in phase 1 and, especially, in phase 2, just like the rules in CRS. The rules of a plugin are separated into a rule file that is loaded before the CRS rules are loaded and a rule file with rules to be executed after the CRS rules are executed.
Optionally, a plugin can also have a separate configuration file with rules that configure the plugin, just like the crs-setup.conf configuration file.
The order of execution is as follows:
CRS configuration
Plugin configuration
Plugin rules before CRS rules
CRS rules
Plugin rules after CRS rules
This can be mapped almost 1:1 to the Includes involved:
Include crs/crs-setup.conf
Include crs/plugins/*-config.conf
Include crs/plugins/*-before.conf
Include crs/rules/*.conf
Include crs/plugins/*-after.conf
The two existing CRS Include statements are complemented with three additional generic plugin Includes. This means CRS is configured first, then the plugins are configured (if any), then the first batch of plugin rules are executed, followed by the main CRS rules, and finally the second batch of plugin rules run, after CRS.
How to Install a Plugin
The first step is to prepare the plugin folder.
CRS 4.x will come with a plugins folder next to the rules folder. When using an older CRS release without a plugins folder, create one and place three empty config files in it (e.g. by using the shell command touch):
These empty rule files ensure that the web server does not fail when Include-ing *.conf if there are no plugin files present.
Info
Apache supports the IncludeOptional directive, but that is not available on all web servers, so Include is used here in the interests of having consistent and simple documentation.
For the installation, there are two methods:
Method 1: Copying the plugin files
This is the simple way. Download or copy the plugin files, which are likely rules and data files, and put them in the plugins folder of the CRS installation, as prepared above.
There is a chance that a plugin configuration file comes with a .example suffix in the filename, like the crs-setup.conf.example configuration file in the CRS release. If that’s the case then rename the plugin configuration file by removing the suffix.
Be sure to look at the configuration file and see if there is anything that needs to be configured.
Finally, reload the WAF and the plugin should be active.
Method 2: Placing symbolic links to separate plugin files downloaded elsewhere
This is the more advanced setup and the one that’s in sync with many Linux distributions.
With this approach, download the plugin to a separate location and put a symlink to each individual file in the plugins folder. If the plugin’s configuration file comes with a .example suffix then that file needs to be renamed first.
With this approach it’s easier to upgrade and downgrade a plugin by simply changing the symlink to point to a different version of the plugin. It’s also possible to git checkout the plugin and pull the latest version when there’s an update. It’s not possible to do this in the plugins folder itself, namely when multiple plugins need to be installed side by side.
This symlink setup also makes it possible to git clone the latest version of a plugin and update it in the future without further ado. Be sure to pay attention to any updates in the config file, however.
If updating plugins this way, there’s a chance of missing out a new variable that’s defined in the latest version of the plugin’s config file. Plugin authors should make sure this is not happening to plugin users by adding a rule that checks for the existence of all config variables in the Before-File. Examples of this can be found in CRS file REQUEST-901-INITIALIZATION.conf.
How to Disable a Plugin
Disabling a plugin is simple. Either remove the plugin files in the plugins folder or, if installed using the symlink method, remove the symlinks to the real files. Working with symlinks is considered to be a ‘cleaner’ approach, since the plugin files remain available to re-enable in the future.
Alternatively, it is also valid to disable a plugin by renaming a plugin file from plugin-before.conf to plugin-before.conf.disabled.
Conditionally enable plugins for multi-application environments
If CRS is installed on a reverse-proxy or a web server with multiple web applications, then you may wish to only enable certain plugins (such as rule exclusion plugins) for certain virtual hosts (VirtualHost for Apache httpd, Server context for Nginx). This ensures that rules designed for a specific web application are only enabled for the intended web application, reducing the scope of any possible bypasses within a plugin.
Most plugins provide an example to disable the plugin in the file plugin-config.conf, you can define the WebAppID variable for each virtual host and then disable the plugin when the WebAppID variable doesn’t match.
Template Plugin: This is the example plugin for getting started.
Auto-Decoding Plugin: This uses ModSecurity transformations to decode encoded payloads before applying CRS rules at PL 3 and double-decoding payloads at PL 4.
Antivirus Plugin: This helps to integrate an antivirus scanner into CRS.
Body-Decompress Plugin: This decompresses/unzips the response body for inspection by CRS.
Fake-Bot Plugin: This performs a reverse DNS lookup on IP addresses pretending to be a search engine.
Incubator Plugin: This plugin allows non-scoring rules to be tested in production before pushing them into the mainline.
How to Write a Plugin
For information on writing a new plugin, refer to the development documentation on writing plugins.
Collection Timeout
If plugins need to work with collections and set a custom SecCollectionTimeout outside of the default 3600 seconds defined by the ModSecurity engine, the plugin should either set it in its configuration or indicate the desired value in the plugin documentation. CRS used to define SecCollectionTimeout in crs-setup.conf before but removed this setting with the introduction of plugins for CRS v4. That’s because CRS itself does not work with collections anymore.
Writing Plugins
The CRS plugin mechanism allows the rule set to be extended in specific, experimental, or unusual ways. This page explains how to write a new plugin to extend CRS.
How to Write a Plugin
Is a Plugin the Right Approach for a Given Rule Problem?
This is the first and most important question to ask.
CRS is a generic rule set. The rule set has no awareness of the particular setup it finds itself deployed in. As such, the rules are written with caution and administrators are given the ability to steer the behavior of CRS by setting the anomaly threshold accordingly. An administrator writing their own rules knows a lot more about their specific setup, so there’s probably no need to be as cautious. It’s also probably futile to write anomaly scoring rules in this situation. Anomaly scoring adds little value if an administrator knows that everybody issuing a request to /no-access, for example, is an attacker.
In such a situation, it’s better to write a simple deny-rule that blocks said requests. There’s no need for a plugin in most situations.
Plugin Writing Guidance
When there really is a good use case for a plugin, it’s recommended to start with a clone of the template plugin. It’s well documented and a good place to start from.
Plugins are a new idea for CRS. As such, there aren’t currently any strict rules about what a plugin is and isn’t allowed to do. There are definitely fewer rules and restrictions for writing plugin rules than for writing a mainline CRS rule, which is becoming increasingly strict as the project evolves. This means that it’s basically possible to do anything in a plugin, especially when there’s no plan to contribute the plugin to the CRS project.
When it is planned to contribute a plugin back to the CRS project, the following guidance will help:
Try to keep plugins separate. Try not to interfere with other plugins and make sure that any other plugin can run next to yours.
Be careful when interfering with CRS. It’s easy to disrupt CRS by excluding essential rules or by messing with variables.
Keep an eye on performance and think of use cases.
Anomaly Scoring: Getting the Phases Right
The anomaly scores are only initialized in the CRS rules file REQUEST-901-INITIALIZATION.conf. This happens in phase 1, but it still happens after a plugin’s *-before.conf file has been executed for phase 1. As a consequence, if anomaly scores are set there then they’ll be overwritten in CRS phase 1.
The effect for phase 2 anomaly scoring in a plugin’s *-after.conf file is similar. It happens after the CRS request blocking happens in phase 2. This can mean a plugin raises the anomaly score after the blocking decision. This might result in a higher anomaly score in the log file and confusion as to why the request was not blocked.
What to do is as follows:
Scoring in phase 1: Put in the plugin’s After-File (and be aware that early blocking won’t work).
Scoring in phase 2: Put in the plugin’s Before-File.
Plugin Use of Persistent Collections: ModSecurity SecCollectionTimeout
If a plugin uses persistent collections (stores stateful information across multiple requests, e.g., to implement DoS protection functionality), it is important to note that CRS does not change the default value (3600) for the ModSecurity SecCollectionTimeout directive. Plugin authors must instruct users to set the directive to an appropriate value if the plugin requires a value that differs from the default. A plugin should never actively set SecCollectionTimeout, as other plugins may specify different values for the directive and the choice for the effective value must be made by the user.
Quality Guarantee
The official CRS plugins are separated from third party plugins. The rationale is to keep the quality of official plugins on par with the quality of the CRS project itself. It’s not possible to guarantee the quality of third party plugins as their code is not under the control of the CRS project. Third party plugins should be examined and considered separately to decide whether their quality is sufficient for use in production.
How to Integrate a Plugin into the Official Registry
Plugins should be developed and refined until they are production-ready. The next step is to open a pull request at the plugin registry. Any free rule ID range can be used for a new plugin. The plugin will then be reviewed and assigned a block of rule IDs. Afterwards, the plugin will be listed as a new third party plugin.
Advanced Topics
The content here doesn’t fit anywhere else just yet. This whole section will probably be reworked and is only temporary.
Subsections of Advanced Topics
Self-Contained Mode
Self-Contained Mode
Traditional Detection Mode (deprecated)
The default mode in CRS 3.x is Anomaly Scoring mode, you can verify this
is your mode by checking that the SecDefaultAction line in the
crs-setup.conf file usees the pass action:
SecDefaultAction "phase:2,pass,log"
Warning
From version 3.0 onwards, Anomaly Scoring is the default detection mode. Traditional detection mode is discouraged.
(AH) Summary: traditional, self-contained mode: a rule match (alert) causes an immediate block.
Traditional Detection Mode (or IDS/IPS mode) is the old default
operating mode. This is the most basic operating mode where all of the
rules are “self-contained”. In this mode there is no intelligence is
shared between rules and each rule has no information about any previous
rule matches. That is to say, in this mode, if a rule triggers, it will
execute any disruptive/logging actions specified on the current rule.
Configuring Traditional Mode
If you want to run the CRS in Traditional mode, you can do this easily
by modifying the SecDefaultAction directive in the crs-setup.conf file
to use a disruptive action other than the default 'pass', such as
deny:
# Updated To Enable Traditional ModeSecDefaultAction "phase:2,deny,status:403,log"
Pros and Cons of Traditional Detection Mode
Pros
The functionality of this mode is much easier for a new user to
understand.
Better performance (lower latency and resource usage) as the first disruptive
match will stop further processing.
Cons
Not all rules are executed, so not all rules that could have been
triggered will match. As such, logging information on a successful
block is less useful, as only the first detected threat is logged
Not every site has the same risk tolerance
Lower severity alerts may not trigger traditional mode
Single low severity alerts may not be deemed critical enough to
block, but multiple lower severity alerts in aggregate could be
Pros and Cons of Anomaly Scoring Detection Mode
Pros
An increased confidence in blocking - since more detection rules
contribute to the anomaly score, the higher the score, the more
confidence you can have in blocking malicious transactions.
Flexibility for setting blocking policies. Allows users to set a threshold that is appropriate for them -
different sites may have different thresholds for blocking.
Allows several low severity events to trigger alerts while
individual ones are suppressed.
One correlated event helps alert management.
Exceptions may be handled by either increasing the overall anomaly
score threshold, or by adding local custom exceptions file
More accurate log information, as all rules execute
Cons
More complex for the average user.
Log monitoring scripts may need to be updated for proper analysis
Log Handling
A full operational guide on how to handle and consume the logs emitted by CRS and its compatible WAF engines will be written in the future.
Kubernetes Ingress Controllers
A Kubernetes cluster can use different types of ingress controllers to expose Kubernetes services outside the cluster. Some ingress controllers include built-in support for using CRS, as this page outlines.
The upstream project provides many examples of how to configure the controller. These are a good starting point.
Info
All of the configuration is done via the ConfigMap. All options for ModSecurity and CRS can be found in the annotations list.
The default ModSecurity configuration file is located at /etc/nginx/modsecurity/modsecurity.conf. This is the only file located in this directory and it contains the default recommended configuration. Using a volume, this file can be replaced with the desired configuration. To enable the ModSecurity feature, specify enable-modsecurity: "true" in the configuration ConfigMap.
The directory /etc/nginx/owasp-modsecurity-crs contains the CRS repository. Use enable-owasp-modsecurity-crs: "true" to enable use of the CRS rules.
Common Problems
Tip
To get individual rule alerts, if they’re not visible in the error log (for example, if only log entries for rule 949110 are present in the log file), make sure to set the annotation error-log-level: warn.
Development
Subsections of Development
Contribution Guidelines
The CRS project values third party contributions. To make the contribution process as easy as possible, a helpful set of contribution guidelines are in place which all contributors and developers are asked to adhere to.
Open a new issue for the contribution, assuming a similar issue doesn’t already exist.
Clearly describe the issue, including steps to reproduce if reporting a bug.
Specify the CRS version in question if reporting a bug.
Bonus points for submitting tests along with the issue.
Fork the repository on GitHub and begin making changes there.
Signed commits are preferred. (For more information and help with this, refer to the GitHub documentation).
Making Changes
Base any changes on the latest dev branch (e.g., main).
Create a topic branch for each new contribution.
Fix only one problem at a time. This helps to quickly test and merge submitted changes. If intending to fix multiple unrelated problems then use a separate branch for each problem.
Make commits of logical units.
Make sure commits adhere to the contribution guidelines presented in this document.
Action lists in rules must always be enclosed in double quotes for readability, even if there is only one action (e.g., use "chain" instead of chain, and "ctl:requestBodyAccess=Off" instead of ctl:requestBodyAccess=Off).
Always use numbers for phases instead of names.
Format all use of SecMarker using double quotes, using UPPERCASE, and separating words with hyphens. For example:
Rule actions should appear in the following order, for consistency:
id
phase
allow | block | deny | drop | pass | proxy | redirect
status
capture
t:xxx
log
nolog
auditlog
noauditlog
msg
logdata
tag
sanitiseArg
sanitiseRequestHeader
sanitiseMatched
sanitiseMatchedBytes
ctl
ver
severity
multiMatch
initcol
setenv
setvar
expirevar
chain
skip
skipAfter
Rule operators must always be explicitly specified. Although ModSecurity defaults to using the @rx operator, for clarity @rx should always be explicitly specified when used. For example, write:
SecRule ARGS "@rx foo" "id:1,phase:1,pass,t:none"
instead of
SecRule ARGS "foo" "id:1,phase:1,pass,t:none"
For CRS Documentation Contributions
Directory naming: Use lowercase letters and hyphens to separate words. For example:
Inner-link referencing should be used with the following format:
# general markdown format
{{< ref "path/to/file.md" >}}
# this will point to the directory 2-how-crs-works
{{< ref "2-how-crs-works" >}}
# this will point to the .md
{{< ref "2-3-false-positives-and-tuning.md" >}}
Variable Naming Conventions
Variable names should be lowercase and should use the characters a-z, 0-9, and underscores only.
To reflect the different syntax between defining a variable (using setvar) and using a variable, the following visual distinction should be applied:
Variable definition: Lowercase letters for collection name, dot as the separator, variable name. E.g.: setvar:tx.foo_bar_variable
Variable use: Capital letters for collection name, colon as the separator, variable name. E.g.: SecRule TX:foo_bar_variable
Writing Regular Expressions
Use the following character class, in the stated order, to cover alphanumeric characters plus underscores and hyphens: [a-zA-Z0-9_-]
Portable Backslash Representation
CRS uses \x5c to represent the backslash \ character in regular expressions. Some of the reasons for this are:
It’s portable across web servers and WAF engines: it works with Apache, Nginx, and Coraza.
It works with the crs-toolchain for building optimized regular expressions.
The older style of representing a backslash using the character class [\\\\] must not be used. This was previously used in CRS to get consistent results between Apache and Nginx, owing to a quirk with how Apache would “double un-escape” character escapes. For future reference, the decision was made to stop using this older method because:
It can be confusing and difficult to understand how it works.
Regular expression engines and libraries based on PCRE use the forward slash / character as the default delimiter. As such, forward slashes are often escaped in regular expression patterns. In the interests of readability, CRS does not escape forward slashes in regular expression patterns, which may seem unusual at first to new contributors.
If testing a CRS regular expression using a third party tool, it may be useful to change the delimiter to something other than / if a testing tool raises errors because a CRS pattern features unescaped forward slashes.
Vertical Tab Representation
CRS uses \x0b to represent the vertical tab in character classes. This is necessary because most regular expressions are generated and simplified using external libraries. These libraries produce output that the generator must convert into a form that is compatible with both PCRE and RE2 compatible engines. In RE2, \s does not include \v (which is the case in PCRE), and needs to be added. However, \v in PCRE expands to a list of vertical characters and is, therefore, not allowed to start range expressions. Since we only care about the vertical tab we use \x0b.
When and Why to Anchor Regular Expressions
Engines running OWASP CRS will use regular expressions to search the input string, i.e., the regular expression engine is asked to find the first match in the input string. If an expression needs to match the entire input then the expression must be anchored appropriately.
Beginning of String Anchor (^)
It is often necessary to match something at the start of the input to prevent false positives that match the same string in the middle of another argument, for example. Consider a scenario where the goal is to match the value of REQUEST_HEADERS:Content-Type to multipart/form-data. The following regular expression could be used:
"@rx multipart/form-data"
HTTP headers can contain multiple values, and it may be necessary to guarantee that the value being searched for is the first value of the header. There are different ways to do this but the simplest one is to use the ^ caret anchor to match the beginning of the string:
"@rx ^multipart/form-data"
It will also be useful to ignore case sensitivity in this scenario:
"@rx (?i)^multipart/form-data"
End of String Anchor ($)
Consider, for example, needing to find the string /admin/content/assets/add/evil in the REQUEST_FILENAME. This could be achieved with the following regular expression:
"@rx /admin/content/assets/add/evil"
If the input is changed, it can be seen that this expression can easily produce a false positive: /admin/content/assets/add/evilbutactuallynot/nonevilfile. If it is known that the file being searched for can’t be in a subdirectory of add then the $ anchor can be used to match the end of the input:
"@rx /admin/content/assets/add/evil$"
This could be made a bit more general:
"@rx /admin/content/assets/add/[a-z]+$"
Matching the Entire Input String
It is sometimes necessary to match the entire input string to ensure that it exactly matches what is expected. It might be necessary to find the “edit” action transmitted by WordPress, for example. To avoid false positives on variations (e.g., “myedit”, “the edit”, “editable”, etc.), the ^ caret and $ dollar anchors can be used to indicate that an exact string is expected. For example, to only match the exact strings edit or editpost:
"@rx ^(?:edit|editpost)$"
Other Anchors
Other anchors apart from ^ caret and $ dollar exist, such as \A, \G, and \Z in PCRE. CRS strongly discourages the use of other anchors for the following reasons:
Not all regular expression engines support all anchors and OWASP CRS should be compatible with as many regular expression engines as possible.
Their function is sometimes not trivial.
They aren’t well known and would require additional documentation.
In most cases that would justify their use the regular expression can be transformed into a form that doesn’t require them, or the rule can be transformed (e.g., with an additional chain rule).
Use Capture Groups Sparingly
Capture groups, i.e., parts of the regular expression surrounded by parentheses (( and )), are used to store the matched information from a string in memory for later use. Capturing input uses both additional CPU cycles and additional memory. In many cases, parentheses are mistakenly used for grouping and ensuring precedence.
To group parts of a regular expression, or to ensure that the expression uses the precedence required, surround the concerning parts with (?: and ). Such a group is referred to as being “non-capturing”. The following will create a capture group:
"@rx a|(b|c)d"
On the other hand, this will create a non-capturing group, guaranteeing the precedence of the alternative without capturing the input:
"@rx a|(?:b|c)d"
Lazy Matching
The question mark ? can be used to turn “greedy” quantifiers into “lazy” quantifiers, i.e., .+ and .* are greedy while .+? and .*? are lazy. Using lazy quantifiers can help with writing certain expressions that wouldn’t otherwise be possible. However, in backtracking regular expression engines, like PCRE, lazy quantifiers can also be a source of performance issues. The following is an example of an expression that uses a lazy quantifier:
This expression matches cookie values in HTML to detect session fixation attacks. The input string could be document.cookie = "name=evil; domain=https://example.com";.
The lazy quantifiers in this expression are used to reduce the amount of backtracking that engines such as PCRE have to perform (others, such as RE2, are not affected by this). Since the asterisk * is greedy, .* would match every character in the input up to the end, at which point the regular expression engine would realize that the next character, ;, can’t be matched and it will backtrack to the previous position (;). A few iterations later, the engine will realize that the character d from domain can’t be matched and it will backtrack again. This will happen again and again, until the ; at evil; is found. Only then can the engine proceed with the next part of the expression.
Using lazy quantifiers, the regular expression engine will instead match as few characters as possible. The engine will match (a space), then look for ; and will not find it. The match will then be expanded to = and, again, a match of ; is attempted. This continues until the match is = "name=evil and the engine finds ;. While lazy matching still includes some work, in this case, backtracking would require many more steps.
Lazy matching can have the inverse effect, though. Consider the following expression:
"@rx (?i)\b(?:s(?:tyle|rc)|href)\b[\s\S]*?="
It matches some HTML attributes and then expects to see =. Using a somewhat contrived input, the lazy quantifier will require more steps to match then the greedy version would: style =. With the lazy quantifier, the regular expression engine will expand the match by one character for each of the space characters in the input, which means 21 steps in this case. With the greedy quantifier, the engine would match up to the end in a single step, backtrack one character and then match = (note that = is included in [\s\S]), which makes 3 steps.
To summarize: be very mindful about when and why you use lazy quantifiers in your regular expressions.
Possessive Quantifiers and Atomic Groups
Lazy and greedy matching change the order in which a regular expression engine processes a regular expression. However, the order of execution does not influence the backtracking behavior of backtracking engines.
Possessive quantifiers (e.g., x++) and atomic groups (e.g., (?>x)) are tools that can be used to prevent a backtracking engine from backtracking. They can be used for performance optimization but are only supported by backtracking engines and, therefore, are not permitted in CRS rules.
Writing Regular Expressions for Non-Backtracking Compatibility
Traditional regular expression engines use backtracking to solve some additional problems, such as finding a string that is preceded or followed by another string. While this functionality can certainly come in handy and has its place in certain applications, it can also lead to performance issues and, in uncontrolled environments, open up possibilities for attacks (the term “ReDoS” is often used to describe an attack that exhausts process or system resources due to excessive backtracking).
OWASP CRS tries to be compatible with non-backtracking regular expression engines, such as RE2, because:
Non-backtracking engines are less vulnerable to ReDoS attacks.
Non-backtracking engines can often outperform backtracking engines.
CRS aims to leave the choice of the engine to the user/system.
To ensure compatibility with non-backtracking regular expression engines, the following operations are not permitted in regular expressions:
positive lookahead (e.g., (?=regex))
negative lookahead (e.g., (?!regex))
positive lookbehind (e.g., (?<=regex))
negative lookbehind (e.g., (?<!regex))
named capture groups (e.g., (?P<name>regex))
backreferences (e.g., \1)
named backreferences (e.g., (?P=name))
conditionals (e.g., (?(regex)then|else))
recursive calls to capture groups (e.g., (?1))
possessive quantifiers (e.g., (?:regex)++)
atomic (or possessive) groups (e.g., (?>regex))
This list is not exhaustive but covers the most important points. The RE2 documentation includes a complete list of supported and unsupported features that various engines offer.
When and How to Optimize Regular Expressions
Optimizing regular expressions is hard. Often, a change intended to improve the performance of a regular expression will change the original semantics by accident. In addition, optimizations usually make expressions harder to read. Consider the following example of URL schemes:
mailto|mms|mumble|maven
An optimized version (produced by the crs-toolchain) could look like this:
m(?:a(?:ilto|ven)|umble|ms)
The above expression is an optimization because it reduces the number of backtracking steps when a branch fails. The regular expressions in the CRS are often comprised of lists of tens or even hundreds of words. Reading such an expression in an optimized form is difficult: even the simple optimized example above is difficult to read.
In general, contributors should not try to optimize contributed regular expressions and should instead strive for clarity. New regular expressions will usually be required to be submitted as a .ra file for the crs-toolchain to process. In such a file, the regular expression is decomposed into individual parts, making manual optimizations much harder or even impossible (and unnecessary with the crs-toolchain). The crs-toolchain performs some common optimizations automatically, such as the one shown above.
Whether optimizations make sense in a contribution is assessed for each case individually.
Rules Compliance with Paranoia Levels
The rules in CRS are organized into paranoia levels (PLs) which makes it possible to define how aggressive CRS is. See the documentation on paranoia levels for an introduction and more detailed explanation.
Each rule that is placed into a paranoia level must contain the tag paranoia-level/N, where N is the PL value, however this tag can only be added if the rule does not use the nolog action.
The types of rules that are allowed at each paranoia level are as follows:
PL 0:
ModSecurity / WAF engine installed, but almost no rules
PL 1:
Default level: keep in mind that most installations will normally use this level
Any complex, memory consuming evaluation rules will surely belong to a higher level, not this one
CRS will normally use atomic checks in single rules at this level
Confirmed matches only; all scores are allowed
No false positives / low false positives: try to avoid adding rules with potential false positives!
Matches that cause false positives are limited to using scores notice or warning
Low false positive rates
False negatives are not desirable
PL 3:
Chain usage with complex regular expression look arounds and macro expansions are allowed
Confirmed matches use scores warning or critical
Matches that cause false positives are limited to using score notice
False positive rates are higher but limited to multiple matches (not single strings)
False negatives should be a very unlikely accident
PL 4:
Every item is inspected
Variable creations are allowed to avoid engine limitations
Confirmed matches use scores notice, warning, or critical
Matches that cause false positives are limited to using scores notice or warning
False positive rates are higher (even on single strings)
False negatives should not happen at this level
Check everything against RFCs and allow listed values for the most popular elements
ID Numbering Scheme
The CRS project uses the numerical ID rule namespace from 900,000 to 999,999 for CRS rules, as well as 9,000,000 to 9,999,999 for default CRS rule exclusion packages and plugins.
Rules applying to the incoming request use the ID range 900,000 to 949,999.
Rules applying to the outgoing response use the ID range 950,000 to 999,999.
The rules are grouped by the vulnerability class they address (SQLi, RCE, etc.) or the functionality they provide (e.g., initialization). These groups occupy blocks of thousands (e.g., SQLi: 942,000 - 942,999). These grouped rules are defined in files dedicated to a single group or functionality. The filename takes up the first three digits of the rule IDs defined within the file (e.g., SQLi: REQUEST-942-APPLICATION-ATTACK-SQLI.conf).
The individual rules within each file for a vulnerability class are organized by the paranoia level of the rules. PL 1 is first, then PL 2, etc.
The ID block 9xx000 - 9xx099 is reserved for use by CRS helper functionality. There are no blocking or filtering rules in this block.
Among the rules providing CRS helper functionality are rules that skip other rules depending on the paranoia level. These rules always use the following reserved rule IDs: 9xx011 - 9xx018, with very few exceptions.
The blocking and filter rules start at 9xx100 with a step width of 10, e.g., 9xx100, 9xx110, 9xx120, etc.
The ID of a rule does not correspond directly with its paranoia level. Given the size of rule groups and how they’re organized by paranoia level (starting with the lower PL rules first), PL 2 and above tend to be composed of rules with higher ID numbers.
Stricter Siblings
Within a rule file / block, there are sometimes smaller groups of rules that belong together. They’re closely linked and very often represent copies of the original rules with a stricter limit (alternatively, they can represent the same rule addressing a different target in a second rule, where this is necessary). These are stricter siblings of the base rule. Stricter siblings usually share the first five digits of the rule ID and raise the rule ID by one, e.g., a base rule at 9xx160 and a stricter sibling at 9xx161.
Stricter siblings often have different paranoia levels. This means that the base rule and the stricter siblings don’t usually reside next to each another in the rule file. Instead, they’re ordered by paranoia level and are linked by the first digits of their rule IDs. It’s good practice to introduce all stricter siblings together as part of the definition of the base rule: this can be done in the comments of the base rule. It’s also good practice to refer back to the base rule with the keywords “stricter sibling” in the comments of the stricter siblings themselves. For example: “…This is performed in two separate stricter siblings of this rule: 9xxxx1 and 9xxxx2”, and “This is a stricter sibling of rule 9xxxx0.”
Writing Tests
Each rule should be accompanied by tests. Rule tests are an invaluable way to check that a rule behaves as expected:
Does the rule correctly match against the payloads and behaviors that the rule is designed to detect? (Positive tests)
Does the rule correctly not match against legitimate requests, i.e., the rule doesn’t cause obvious false positives? (Negative tests)
Rule tests also provide an excellent way to test WAF engines and implementations to ensure they behave and execute CRS rules as expected.
The rule tests are located under tests/regression/tests. Each CRS rule file has a corresponding directory and each individual rule has a corresponding YAML file containing all the tests for that rule. For example, the tests for rule 911100 (Method is not allowed by policy) are in the file REQUEST-911-METHOD-ENFORCEMENT/911100.yaml.
This test will succeed if the log contains an entry for rule 932230, which would indicate that the rule in question matched and generated an alert.
It’s important that tests consistently include the HTTP header fields Host, User-Agent, and Accept. CRS includes rules that detect if these headers are missing or empty, so these headers should be included in each test to avoid unnecessarily causing those rules to match. Ideally, each positive test should causeonlythe rule in question to match.
The rule’s description field, desc, is important. It should describe what is being tested: what should match, what should not match, etc. It is often a good idea to use the YAML literal string scalar form, as it makes it easy to write descriptions spanning multiple lines:
- test_id: 1desc: | This is the first line of the description.
On the second line, we might see the payload.
NOTE: this is something important to take into account.stages:
#...
This test will succeed if the log does not contain an entry for rule 932260, which would indicate that the rule in question did not match and so did not generate an alert.
Encoded Request
It is possible to encode an entire test request. This encapsulates the request and means that the request headers and payload don’t need to be explicitly declared. This is useful when a test request needs to use unusual bytes which might break YAML parsers, or when a test request must be intentionally malformed in a way that is impossible to describe otherwise. An encoded request is sent exactly as intended.
The encoded_request field expects a complete request in base64 encoding:
encoded_request: <Base64 string>
For example:
encoded_request: "R0VUIFwgSFRUUA0KDQoK"
where R0VUIFwgSFRUUA0KDQoK is the base64-encoded equivalent of GET \ HTTP\r\n\r\n.
Using The Correct HTTP Endpoint
The CRS project uses Albedo as the backend server for tests. This backend provides one dedicated endpoint for each HTTP method. Tests should target these endpoints to:
improve test throughput (prevent HTML from being returned by the backend)
specify responses when testing response rules
In general, test URIs can be arbitrary. Albedo will respond with 200 OK and an empty body to any requests that don’t match any of the endpoints explicitly defined by Albedo. These are:
/capabilities: describes capabilities of the used Albedo version
/reflect: used to specify the response that Albedo should return
Former versions of CRS dynamically included the HTTP response body in the audit log via special ctl statements on certain individual response rules. This was never applied in a systematic way and, regardless, CRS should not change the format of the audit log by itself, namely because this can lead to information leakages. Therefore, the use of ctl:auditLogParts=+E or any other form of ctl:auditLogParts is not allowed in CRS rules.
Non-Rules General Guidelines
Remove trailing spaces from files (if they’re not needed). This will make linters happy.
EOF should have an EOL.
The pre-commit framework can be used to check for and fix these issues automatically. First, go to the pre-commit website and download the framework. Then, after installing, use the command pre-commit install so that the tools are installed and run each time a commit is made. CRS provides a config file that will keep the repository clean.
crs-toolchain
The crs-toolchain is the CRS developer’s utility belt — the Swiss army knife for CRS development. It provides a single point of entry and a consistent interface for a range of different tools. Its core functionality (owed to the great rassemble-go, which is itself based on the brain-melting Regexp::Assemble Perl module) is to assemble individual parts of a regular expression into a single expression (with some optimizations).
The current stable release is v2.7.0 (as of December 2025).
Setup
Method 1: Pre-built Binaries (Recommended)
The recommended way to get the tool is using one of the pre-built binaries from GitHub. Navigate to the latest release and download the package for your platform along with the crs-toolchain-checksums.txt file.
Available formats:
Linux: .deb, .rpm, .tar.gz, and .apk packages
macOS: .tar.gz archives for both Intel and Apple Silicon
Windows: .zip and .tar.gz archives
To verify the integrity of the binary/archive, navigate to the directory where the two files are stored and verify that the checksum matches:
cd ~/Downloads
shasum -a 256 -c crs-toolchain-checksums.txt 2>&1 | grep OK
The output should look like the following (depending on the binary/archive downloaded):
crs-toolchain-2.7.0_amd64.deb: OK
Method 2: Install with Go
Note
This method requires Go 1.19 or higher installed on your system.
If a current Go environment is present, install the latest version directly:
go install github.com/coreruleset/crs-toolchain/v2@latest
Provided that the Go binaries are on the PATH (typically ~/go/bin), the toolchain can now be run from anywhere:
crs-toolchain --version
Method 3: Self-Update
Once you have crs-toolchain installed, you can update it to the latest version using the built-in self-update command:
crs-toolchain util self-update
This will automatically download and install the latest release for your platform.
Verify Installation
After installation, verify that crs-toolchain is working correctly:
# Check versioncrs-toolchain --version
# View available commandscrs-toolchain --help
Test the Toolchain
Test the regex assembly functionality by running the following in a shell:
This demonstrates that the tool successfully assembled multiple regular expression alternatives into an optimized single expression.
Configuration and Options
Adjusting the Logging Level
The level of logging can be adjusted with the --log-level global flag. This affects the verbosity of output for all commands.
Available levels (from most to least verbose):
trace - Most detailed, includes all internal operations
debug - Detailed debugging information
info - General informational messages (default)
warn - Warning messages only
error - Error messages only
fatal - Fatal errors only
panic - Panic-level errors only
disabled - No logging output
Usage:
# Run with debug loggingcrs-toolchain --log-level debug regex generate 942170# Run with minimal outputcrs-toolchain --log-level error regex update --all
Global Flags
In addition to --log-level, the following global flags are available for all commands:
crs-toolchain --help # Show help for all commandscrs-toolchain --version # Show version informationcrs-toolchain <command> --help # Show help for a specific command
Recent Releases and Improvements
Version 2.7.0 (December 2024)
Release automation improvements
Bug fixes for semver parsing
Enhanced meta character escaping
Security dependency updates for crypto and compression libraries
Version 2.6.0 (September 2024)
Integrated wordnet database functionality for fp-finder utility
Improved false positive detection capabilities
Routine dependency maintenance
Version 2.5.0 (August 2024)
Command refactoring for better performance
Enabled stdin support for fp-finder command
GitHub Actions and Alpine Linux updates
Version 2.4.0 (May 2024)
New feature:util fp-finder command for detecting false positives
Added PR templates
Improved regex comparison functionality
Version 2.3.x Series (January-April 2024)
Enhanced format validation to fail on unnecessary uppercase character classes
Fixed Unicode character hex representation issues
Added warnings for uppercase in case-insensitive patterns
Removed mage build tool dependency
Restricted evasion modifiers usage
Tip
To see the full release history and detailed changelogs, visit the releases page on GitHub.
Getting Help
Built-in Documentation
Read the built-in help text for comprehensive documentation:
The regex command provides sub-commands for everything surrounding regular expressions, especially the “assembly” of regular expressions from a specification of its components. This is the most commonly used feature of crs-toolchain for CRS development.
Generates an optimized regular expression from a list of expression components. This command reads from regex assembly (.ra) files and produces an assembled, optimized expression.
Usage:
# Generate from rule ID (reads from regex-assembly/<rule-id>.ra)crs-toolchain regex generate 942170# Generate from stdincat regex-assembly/942170.ra | crs-toolchain regex generate -
# Generate from a specific filecrs-toolchain regex generate --file path/to/942170.ra
Compares the generated expression against the current expression in the rule files. This is useful for verifying that changes to regex assembly files will produce the expected output.
Usage:
# Compare single rulecrs-toolchain regex compare 942170# Compare all rulescrs-toolchain regex compare --all
The output will show:
Whether the expressions match
Differences between current and generated expressions
Any formatting or optimization changes
update
Updates rule files directly with newly generated expressions. This command modifies the actual CRS rule configuration files.
Warning
This command modifies files in place. Make sure you have committed your changes or have a backup before running update commands.
Usage:
# Update single rulecrs-toolchain regex update 942170# Update all rules with .ra filescrs-toolchain regex update --all
# Dry-run to see what would be updated (without making changes)crs-toolchain regex update --all --dry-run
format
Checks and formats regex assembly (.ra) files according to CRS standards. This ensures consistent formatting across all regex assembly files.
Usage:
# Check formatting for all .ra filescrs-toolchain regex format --all
# Format a specific rulecrs-toolchain regex format 942170# Check only (report violations without fixing)crs-toolchain regex format --all --check
Format checks include:
Proper line endings
Consistent indentation
Avoiding unnecessary uppercase character classes (added in v2.3.3)
Warning about uppercase in case-insensitive patterns (added in v2.2.0)
Common Workflow
A typical workflow when modifying regular expressions:
# 1. Edit the .ra filevim regex-assembly/942170.ra
# 2. Check formattingcrs-toolchain regex format 942170# 3. Generate and compare to see the resultcrs-toolchain regex compare 942170# 4. If satisfied, update the rule filecrs-toolchain regex update 942170# 5. Test the changes# (run your tests here)
The util Command
The util command includes sub-commands that are used from time to time and do not fit nicely into any of the other groups. Available sub-commands:
renumber-tests
Used to simplify maintenance of the regression tests. Since every test has a consecutive number within its file, adding or removing tests can disrupt numbering. This command will renumber all tests within each test file consecutively.
Usage:
crs-toolchain util renumber-tests
fp-finder
The false positive finder utility helps identify potential false positives in CRS rules. This command analyzes test data and can process input from stdin or files to detect patterns that might trigger false positives.
Added in: v2.4.0 (with wordnet database integration in v2.6.0)
Usage:
# Run fp-finder with stdin inputecho "test data" | crs-toolchain util fp-finder -
# Run fp-finder with file inputcrs-toolchain util fp-finder <test-file>
This tool is particularly useful for:
Identifying problematic patterns before deployment
Testing rule changes against known good traffic
Validating that rule modifications don’t introduce new false positives
self-update
Updates the crs-toolchain to the latest available version. This command automatically downloads and installs the newest release for your platform.
Usage:
crs-toolchain util self-update
The command will:
Check for the latest release on GitHub
Download the appropriate binary for your platform
Replace the current installation with the new version
Verify the update was successful
The chore Command
The chore command provides maintenance utilities primarily used by CRS maintainers and release managers.
release
Manages the release process for crs-toolchain, including version tagging and release artifact generation.
Usage:
crs-toolchain chore release
update-copyright
Updates copyright year information across the project files.
Usage:
crs-toolchain chore update-copyright
The completion Command
The completion command generates shell completion scripts to enable tab completion for crs-toolchain commands in your shell.
After installing shell completion, you may need to restart your shell or source your shell configuration file for the changes to take effect.
How completion is enabled and where completion scripts are sourced from depends on your shell and environment. Please consult the documentation of the shell you’re using for specific details.
Assembling Regular Expressions
The CRS team uses a custom specification format to specify how a regular expression is to be generated from its components. This format enables reuse across different files, explanation of choices and techniques with comments, and specialized processing.
Specification Format
The files containing regular expression specifications (.ra suffix, under regex-assembly) contain one regular expression per line. These files are meant to be processed by the crs-toolchain.
Example
The following is an example of what an assembly file might contain:
##! This line is a comment and will be ignored. The next line is empty and will also be ignored.
##! The next line sets the *ignore case* flag on the resulting expression:
##!+ i
##! The next line is the prefix comment. The assembled expression will be prefixed with its contents:
##!^ \b
##! The next line is the suffix comment. The assembled expression will be suffixed with its contents:
##!$ \W*\(
##! The following two lines are regular expressions that will be assembled:
--a--
__b__
##! Another comment, followed by another regular expression:
^#!/bin/bash
This assembly file would produce the following assembled expression: (?i)\b(?:--a--|__b__|^#!/bin/bash)[^0-9A-Z_a-z]*\(
Comments
Lines starting with ##! are considered comments and will be skipped. Use comments to explain the purpose of a particular regular expression, its use cases, origin, shortcomings, etc. Having more information recorded about individual expressions will allow developers to better understand changes or change requirements, such as when reviewing pull requests.
Empty Lines
Empty lines, i.e., lines containing only white space, will be skipped. Empty lines can be used to improve readability, especially when adding comments.
Flag Marker
A line starting with ##!+ can be used to specify global flags for the regular expression engine. The flags from all lines starting with the flag marker will be combined. The resulting expression will be prefixed with the flags. For example, the two lines
##!+ i
a+b|c
will produce the regular expression (?i)a+b|c.
The following flags are currently supported:
i: ignore case; matches will be case-insensitive
s: make . match newline (\n); this set by ModSecurity anyway and is included here for backward compatibility
Prefix Marker
A line starting with ##!^ can be used to pass a global prefix to the script. The resulting expression will be prefixed with the literal contents of the line. Multiple prefix lines will be concatenated in order. For example, the lines
##!^ \d*\(
##!^ simpson
marge|homer
will produce the regular expression [0-9]*\(simpson(?:marge|homer).
The prefix marker exists for convenience and improved readability. The same can be achieved with the assemble processor.
Suffix Marker
A line starting with ##!$ can be used to pass a suffix to the script. The resulting expression will be suffixed with the literal contents of the line. Multiple suffix lines will be concatenated in order. For example, the lines
##!$ \d*\(
##!$ simpson
marge|homer
will produce the regular expression (?:marge|homer)[0-9]*\(simpson.
The suffix marker exists for convenience and improved readability. The same can be achieved with the assemble processor.
Processor Marker
A line starting with ##!> is a processor directive. The processor marker can be used to preprocess a block of lines.
A line starting with ##!< marks the end of the most recent processor block.
Processor markers have the following general format: <marker> <processor name> [<processor arguments>]. For example: ##!> cmdline unix. The arguments depend on the processor and may be empty.
The following example is intentionanlly simple (and meaningless) to illustrates the use of the markers without adding additionally confusing pieces. Please refer to the following sections for more concrete and useful examples.
Processors may be nested. This enables complex scenarios, such as assembling a smaller expression to concatenate it with another line or block of lines. For example, the following will produce the regular expression line1(?:ab|cd):
##!> assembleline1
##!=>##!> assembleab
cd
##!<##!<
There is no practical limit to the nesting depth.
Each processor block must be terminated with the end marker ##!<, except for the outermost (default) block, where the end marker is optional.
Command Line Evasion processor
Processor name: cmdline
Arguments
unix|windows (required): The processor argument determines the escaping strategy used for the regular expression. Currently, the two supported strategies are Windows cmd (windows) and “unix like” terminal (unix).
Output
One line per line of input, escaped for the specified environment.
Description
The command line evasion processor treats each line as a word (e.g., a shell command) that needs to be escaped.
Lines starting with a single quote ' are treated as literals and will not be escaped.
The special token @ will be replaced with an optional “word ending” regular expression. This can be used in the context of a shell to reduce the number of false positives for a word by requiring a subsequent token to be present. For example: python@.
@ will match:
python<<<'print("hello")'
python <<< 'print("hello")'
@ will not match:
python3<<<'print("hello")'
python3 <<< 'print("hello")'
The special token ~ acts like @ but does not allow any white space tokens to immediately follow the preceding word. This is useful for adding common English words to word lists. For example, there are multiple executable names for “python”, such as python3 or python3.8. These could not be added with python@, as python would be a valid match and create many false positives.
~ will match:
python<<<'print("hello")'
python3 <<< 'print("hello")'
~ will not match:
python <<< 'print("hello")'
The patterns that are used by the command line evasion processor are configurable. The default configuration for the CRS can be found in the toolchain.yaml in the regex-assembly directory of the CRS project.
The following is an example of how the command line evasion processor can be used:
Single line regular expression, where each line of the input is treated as an alternation of the regular expression. Input can also be stored or concatenated by using the two marker comments for input (##!=<) and output (##!=>).
Description
Each line of the input is treated as an alternation of a regular expression, processed into a single line. The resulting regular expression is not optimized (in the strict sense) but is reduced (i.e., common elements may be put into character classes or groups). The ordering of alternations in the output can differ from the order in the file (ordering alternations by length is a simple performance optimization).
This processor can also store the output of a block delimited with the input marker ##!=<, or produce the concatenation of blocks delimited with the output marker ##!=>.
Lines within blocks delimited by input or output markers are treated as alternations, as usual. The input and output markers enable more complex scenarios, such as separating parts of the regular expression in the assembly file for improved readability. Rule 930100, for example, uses separate expressions for periods and slashes, since it’s easier to reason about the differences when they are physically separated. The following example is based on rules from 930100:
The above would produce the following, concatenated regular expression:
(?:\x5c|%(?:2f|5c))\.(?:%0[0-1])?
The input marker ##!=< takes an identifier as a parameter and associates the output of the preceding block with the identifier. No output is produced when using the input ##!=< marker. To concatenate the output of a previously stored block, the appropriate identifier must be passed to the output marker ##!=> as an argument. Stored blocks remain in storage until the end of the program and are available globally. Any input stored previously can be retrieved at any nesting level. Both of the following examples produce the output ab:
##!> assemble ab
##!=< myinput##!> assemble##!=> myinput##!<##!<
##!> assemble ab
##!=< myinput##!<##!> assemble##!=> myinput##!<
Rule 930100 requires the following concatenation of rules: <slash rules><dot rules><slash rules>, where slash rules is concatenated twice. The following example produces this sequence by storing the expression for slashes with the identifier slashes, thus avoiding duplication:
Identifier (required): The name of the definition that will be processed by this processor
Replacement (required): The string that replaces the definition identified by identifier
Output
One line per line of input, with all definition strings replaced with the specified replacement.
Description
The definition processor makes it easy to add recurring strings to expressions. This helps reduce maintenance when a definition needs to be updated. It also improves readability as definition strings provide readable and bounded information, where otherwise a regular expression must be read and boundaries must be identified.
The format of definition strings is as follows:
{{identifier}}
The definition string starts with two opening braces, is followed by an identifier, and ends with two closing braces. The identifier format must satisfy the following regular expression:
[a-z-A-Z\d_-]+
An identifier must have at least one character and consist only of upper and lowercase letters a through z, digits 0 through 9, and underscore or dash.
The following example shows how to use the definition processor:
##!> define slashes [/\x5c]regex with {{slashes}}
This would result in the output regex with [/\x5c].
Include processor
Processor name: include
Arguments
Include file name (required): The name of the file to include, without suffix
Suffix replacements (optional): Any number of two-tuples, where the first entry is the suffix to match and the second entry is the replacement. To use, write -- after the include file name. Tuples are space separated
Output
The exact contents of the included file, including processor directives, with suffixes replaced where appropriate. The prefix and suffix markers are not allowed in included files.
Description
The include processor reduces repetition across assembly files. Repeated blocks can be put into a file in the include directory and then be included with the include processor comment. Include files are normal assembly files, hence include files can also contain further include directives. The only restriction is that included files must not contain the prefix or suffix markers. This is a technical limitation in the crs-toolchain.
The contents of an include file could, for example, be the alternation of accepted HTTP methods:
POST
GET
HEAD
This could be included into an assembly file for a rule that adds an additional method:
##!> include http-headersOPTIONS
The resulting regular expression would be (?:POS|GE)T|HEAD|OPTIONS.
Additionally, definition directives of include files are available to the including file. This means that include files can be used as libraries of expressions. For example, an include file called lib.ra could contain the following definitions:
Include file name (required): The name of the file to include, without suffix
Exclude file names (required): One or more names of files to consult for exclusions, without suffix, space separated
Suffix replacements (optional): Any number of two-tuples, where the first entry is the suffix to match and the second entry is the replacement. To use, end the list of exclude file names with --. Tuples are space separated
Output
The contents of the included file as per the include processor, but with all matching lines from the exclude file removed. Suffixes will have been replaced as appropriate.
Description
The include-except processor further improves reusability of include files by removing exact line matches found in any of the listed exclude files from the result. A use case for this scenario is remote command execution where it is desirable to have a single list of commands but where certain commands should be excluded from some rules to avoid false positives. Consider the following list of command words:
cat
wget
who
zless
This list may be usable at paranoia level 2 or 3 but the words cat and who would produce too many false positives at paranoia level 1. To work around this issue, the following exclude file can be used:
cat
who
The regular expression for a rule at paranoia level 1 would then be generated by the following:
##!> include-except command-list pl1-exclude-list
The processor accepts more than one exclude file, each file name separated by a space.
Additionally, the processor can be instructed to replace suffixes of entries in the include file. The use case for this is primarily that we have word lists used together with the cmdline processor, where entries can be suffixed with @ or ~. The same lists can be used in other contexts but then the cmdline suffixes need to be replaced with a regular expression. The following is an example, where @ will be replaced with [\s<>] and ~ with [^\s]:
"" is the special literal used to represent the empty string in suffix replacements. In order to replace a suffix with the empty string one would write, for example:
Suffix replacement is performed after all exclusions have been removed, which means that entries in exclude files must target the verbatim contents of the include file, i.e., some entry@, not some entry[\s<>]
Note that the include-exclude processor does not have a body, thus the end marker is optional.
Development
We have a syntax highlight extension for Visual Studio Code that helps with writing assembly files. Instructions on how to install the extension can be found in the readme of the repository: https://github.com/coreruleset/regexp-assemble-syntax
We have set up a public CRS Sandbox which you can use to send attacks at the CRS. You can choose between various WAF engines and CRS versions. The sandbox parses audit logs and returns our detections in an easy and useful format.
The sandbox is useful for:
integrators and administrators: you can test out our response in case of an urgent security event, such as the Log4j vulnerability;
exploit developers/researchers: if you have devised a payload, you can test beforehand if it will be blocked by the CRS and by which versions;
CRS developers/rule writers: you can quickly check if the CRS catches a (variant of an) exploit without the hassle of setting up your own CRS instance.
An easy way to use the sandbox is to send requests to it with curl, although you can use any HTTPS client.
The sandbox has many options, which you can change by adding HTTP headers to your request. One is very important so we will explain it first; this is the X-Format-Output: txt-matched-rules header. If you add this header to your request, the sandbox will parse the WAF’s output, and return to you the matched CRS rule IDs with descriptions, and the score for your request.
In this example, we sent ?file=/etc/passwd as a GET payload. The CRS should catch the string /etc/passwd which is on our blocklist. Try out the command in a terminal now if you like!
You can send anything you want at the sandbox, for instance, you can send HTTP headers, POST data, use various HTTP methods, et cetera.
If no attack is detected, the sandbox returns an empty result in the requested format (e.g., an empty JSON array [] for json-matched-rules, or an empty response for txt-matched-rules).
The sandbox also adds a X-Unique-Id header to the response. It contains a unique value that you can use to refer to your request when communicating with us. With curl -i you can see the returned headers.
It’s useful to know that you can tweak the sandbox in various ways. If you don’t send any X- headers, the sandbox will use the following defaults.
The default backend is Apache 2 with ModSecurity 2.9.
The default CRS version is the latest release version.
The default Paranoia Level is 1, which is the least strict setting.
By default, the response is the full audit log from the WAF, which is verbose and includes unnecessary information, hence why X-Format-Output: txt-matched-rules is useful.
Changing options
Let’s say you want to try your payload on different WAF engines or CRS versions, or like the output in a different format for automated usage. You can do this by adding the following HTTP headers to your request:
x-crs-version: will pick another CRS version. Available values are latest (default, currently the latest release) and any supported semver version (e.g. 3.3.9).
x-crs-paranoia-level: will run CRS in a given paranoia level. Available values are 1 (default), 2, 3, 4.
x-crs-mode: can be changed to return the http status code from the backend WAF. Default value is blocking (On), and can be changed using detection (will set engine to DetectionOnly). Values are case insensitive.
x-crs-inbound-anomaly-score-threshold: defines the inbound anomaly score threshold. Valid values are any integer > 0, with 5 being the CRS default. ⚠️ Anything different than a positive integer will be taken as 0, so it will be ignored. This only makes sense if blocking mode is enabled (the default now).
x-crs-outbound-anomaly-score-threshold: defines the outbound anomaly score threshold. Valid values are any integer > 0, with 4 being the CRS default. ⚠️ Anything different than a positive integer will be taken as 0, so it will be ignored. This only makes sense if blocking mode is enabled (the default now).
x-backend allows you to select the specific backend web server:
apache (default) will send the request to Apache 2 + ModSecurity 2.9.
nginx will send the request to Nginx + ModSecurity 3.
coraza will send the request to Coraza WAF on Caddy.
x-format-output formats the response to your use-case (human or automation). Available values are:
omitted/default: the WAF’s audit log is returned unmodified as JSON
txt-matched-rules: human-readable list of CRS rule matches, one rule per line
txt-matched-rules-extended: same but with explanation for easy inclusion in publications
html-matched-rules: HTML page with a styled table of matched rules
Invalid x-format-output values default to json-matched-rules.
The header names are case-insensitive.
Tip
If you work with JSON output (either unmodified or matched rules), jq is a useful tool to work with the output, for example you can add | jq . to get a pretty-printed JSON, or use jq to filter and modify the output.
Advanced examples
Let’s say you want to send a payload to CRS version 3.3.9 and choose Nginx + ModSecurity 3 as a backend, because this is what you are interested in. You want to get the output in JSON because you want to process the results with a script. (For now, we use jq to pretty-print it.)
You can also test the same payload across different WAF engines to compare detection behavior:
# Test on Coraza (Caddy-based WAF)curl -H "x-backend: coraza"\
-H "x-format-output: txt-matched-rules"\
'https://sandbox.coreruleset.org/?q=<script>alert(1)</script>'
Let’s say you are working on a vulnerability publication and want to add a paragraph to explain how CRS protects (or doesn’t!) against your exploit. Then the txt-matched-rules-extended can be a useful format for you.
curl -H 'x-format-output: txt-matched-rules-extended'\
https://sandbox.coreruleset.org/?file=/etc/passwd
This payload has been tested against the OWASP CRS
web application firewall. The test was executed using the apache engine and CRS version latest.
The payload is being detected by triggering the following rules:
930120 PL1 OS File Access Attempt
932160 PL1 Remote Command Execution: Unix Shell Code Found
949110 PL1 Inbound Anomaly Score Exceeded (Total Score: 10)980130 PL1 Inbound Anomaly Score Exceeded (Total Inbound Score: 10 - SQLI=0,XSS=0,RFI=0,LFI=5,RCE=5,PHPI=0,HTTP=0,SESS=0): individual paranoia level scores: 10, 0, 0, 0CRS therefore detects this payload starting with paranoia level 1.
Capacity
Please do not send more than 10 requests per second.
We will try to scale in response to demand.
Data and privacy
All requests sent to the sandbox are logged and processed by the sandbox infrastructure. Do not send real personal data, credentials, API keys, or any sensitive information in your requests. By using the sandbox, you acknowledge that submitted request content may be retained and analyzed by the OWASP CRS Team for the purpose of improving CRS rules and sandbox infrastructure. See the CRS Sandbox Security Policy for full details.
Architecture
The sandbox consists of various parts. An NLB (Network Load Balancer) sits in front of the frontend and distributes incoming traffic. The frontend that receives the requests runs on OpenResty (Nginx with Lua). It handles the incoming request, selects and configures the backend running CRS based on the request headers, proxies the request to the backend, and waits for the response. Then it parses the WAF audit log and sends the matched rules back in the format chosen by the user.
There is a backend container for every engine and version. The current backends are:
Backend
Engine
Container
Apache + ModSecurity 2.9
apache
apache-latest, apache-3_3_8
Nginx + ModSecurity 3
nginx
nginx-latest, nginx-3_3_8
Coraza WAF on Caddy
coraza
coraza-latest
The backend writes their JSON audit logs to a shared volume. OpenResty reads the per-transaction audit log file to extract matched rules and format the response. Logs are also collected by Filebeat and sent to an S3 bucket and Elasticsearch for monitoring.
Known issues
In some cases, the sandbox will not properly handle and finish your request.
Malformed HTTP requests: The frontend, OpenResty, is itself a HTTP server which performs parsing of the incoming request. The backend servers running CRS are regular webservers such as Apache and Nginx. Either one of these may reject a malformed HTTP request with an error 400 before it is even processed by CRS. This happens for instance when you try to send an Apache 2.4.50 attack that depended on a URL encoding violation. If you receive an error 400, your request was rejected by the frontend or a backend, and it was not scanned by CRS.
ReDoS: If your request leads to a ReDoS and makes the backend spend too much time to process a regular expression, this leads to a timeout from the backend server. The frontend will cancel the request with an error 502. If you have to wait a long time and then receive an error 502, there was likely a ReDoS situation.
If you have suggestions for extra functionality, a GitHub issue is appreciated.
Testing the Rule Set
Well, you managed to write your rule, but now want to see if if can be added to the CRS? This document should help you to test it using the same tooling the project uses for its tests.
CRS uses go-ftw to run test cases. go-ftw is the successor to the previously used test runner ftw. The CRS project no longer uses ftw but it us still useful for running tests of older CRS versions.
Environments
Before you start to run tests, you should set up your environment. You can use Docker to run a web server with CRS integration or use your existing environment.
Setting up Docker containers
For testing, we use the container images from our project. We “bind mount” the rules in the CRS Git repository to the web server container and then instruct go-ftw to send requests to it.
To test we need two containers: the WAF itself, and a backend, provided in this case by Albedo. The docker-compose.yml in the CRS Git repository is a ready-to-run configuration for testing, to be used with the docker compose command.
Important
The supported platform is ModSecurity 2 with Apache httpd
Let’s start the containers by executing the following command:
docker compose -f tests/docker-compose.yml up -d modsec2-apache
[+] Running 2/2
✔ backend Pulled 2.1s
✔ ff7dc8bdd3d5 Pull complete 1.0s
[+] Running 3/3
✔ Network tests_default Created 0.0s
✔ Container tests-backend-1 Started 0.2s
✔ Container modsec2-apache Started 0.2s
Now let’s see which containers are running now, using docker ps:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0570b291c386 owasp/modsecurity-crs:apache "/bin/sh -c '/bin/cp…"7 seconds ago Up 7 seconds (health: starting) 80/tcp, 0.0.0.0:80->8080/tcp modsec2-apache
50704d5c5762 ghcr.io/coreruleset/albedo:0.0.13 "/usr/bin/albedo --p…"7 seconds ago Up 7 seconds tests-backend-1
Excellent, our containers are running, now we can start our tests.
Using your own environment for testing
If you have your own environment set up, you can configure that for testing. Please follow these instructions to install the WAF server locally.
Note
Remember: The supported platform is ModSecurity 2 with Apache httpd. If you want to run the tests against nginx, you can do that too, but nginx uses libmodsecurity3, which is not fully compatible with Apache httpd + ModSecurity 2.
If you want to run the complete test suite of CRS 4.x with go-ftw, you need to make some modifications to your setup. This is because the test cases for 4.x contain some extra data for responses, letting us test the RESPONSE-* rules too. Without the following steps these tests will fail.
To enable response handling for tests you will need to download an additional tool, albedo.
Start albedo
Albedo is a simple HTTP server used as a reverse-proxy backend in testing web application firewalls (WAFs). go-ftw relies on Albedo to test WAF response rules.
You can start albedo with this command:
./albedo -p 8085
As you can see the HTTP server listens on *:8085, you can check it using:
curl -H "Content-Type: application/json" -d '{"body":"Hello, World from albedo"}'"http://localhost:8085/reflect"Hello, World from albedo%
Check for other features using the url /capabilities on albedo. The reflection feature is mandatory for testing response rules.
Modify webserver’s config
For the response tests you need to set up your web server as a proxy, forwarding the requests to the backend. The following is an example of such a proxy setup.
Before you start to change your configurations, please make a backup!
Apache httpd
Put this snippet into your httpd’s default config (eg. /etc/apache2/sites-enabled/000-default.conf):
ProxyPreserveHost On ProxyPass / http://127.0.0.1:8000/
ProxyPassReverse / http://127.0.0.1:8000/
ServerName localhost
nginx
Put this snippet into the nginx default config (e.g., /etc/nginx/conf.d/default.conf) or replace the existing one:
In both cases (Apache httpd, nginx) you have to change your modsecurity.conf settings. Open that file and find the directive SecResponseBodyMimeType. Modify the arguments:
Now, after restarting the web server all request will be sent to the backend. Let’s start testing.
Go-ftw
Tests are performed using go-ftw. We run our test suite automatically using go-ftw as part of a GitHub workflow. You can easily reproduce that locally, on your workstation.
We strongly suggest to install a pre-compiled binary of go-ftw available on GitHub.
The binary is ready to run and does not require installation. On the releases page you will also find .deb and .rpm packages that can be used for installation on some GNU/Linux systems.
Modern versions of go-ftw have also a self-update command that will simplify updating to newer releases for you!
You can also install pre-compiled binaries by using go install, if you have a Go environment:
go install github.com/coreruleset/go-ftw@latest
This will install the binary into your $HOME/go/bin directory. To compile go-ftw from source, run the following commands:
git clone https://github.com/coreruleset/go-ftw.git
cd go-ftw
go build
This will build the binary in the go-ftw repository.
Now create a configuration file. Because Apache httpd and nginx use different log file paths, and, perhaps, different ports, you may want to create two different configuration files for go-ftw. For details please read go-ftw’s documentation.
Please verify that these settings are correct for your setup, especially the port values.
Running the test suite
Execute the following command to run the CRS test suite with go-ftw against Apache httpd:
Warning
⚠️ If go-ftw is installed from a pre-compiled binary, then you might have to use ftw instead of the go-ftw command.
./go-ftw run --config .ftw.apache.yaml -d ../coreruleset/tests/regression/tests/
🛠️ Starting tests!
🚀 Running go-ftw!
👉 executing tests in file 911100.yaml
running 911100-1: ✔ passed in 239.699575ms (RTT 126.721984ms) running 911100-2: ✔ passed in 63.339213ms (RTT 69.998361ms) running 911100-3: ✔ passed in 64.87875ms (RTT 71.368241ms) running 911100-4: ✔ passed in 77.823772ms (RTT 81.059904ms) running 911100-5: ✔ passed in 64.451749ms (RTT 70.403898ms) running 911100-6: ✔ passed in 67.774327ms (RTT 73.803885ms) running 911100-7: ✔ passed in 65.528094ms (RTT 72.64316ms) running 911100-8: ✔ passed in 66.129563ms (RTT 73.198992ms)👉 executing tests in file 913100.yaml
running 913100-1: ✔ passed in 71.242549ms (RTT 76.803619ms) running 913100-2: ✔ passed in 69.999667ms (RTT 76.617714ms) running 913100-3: ✔ passed in 70.200211ms (RTT 76.92281ms) running 913100-4: ✔ passed in 65.856005ms (RTT 73.328341ms) running 913100-5: ✔ passed in 66.986859ms (RTT 73.494356ms) ...
To run the test suite against nginx, execute the following:
./go-ftw run --config .ftw.nginx.yaml -d ../coreruleset/tests/regression/tests/
🛠️ Starting tests!
🚀 Running go-ftw!
👉 executing tests in file 911100.yaml
running 911100-1: ✔ passed in 851.460335ms (RTT 292.802335ms) running 911100-2: ✔ passed in 53.748811ms (RTT 66.798867ms) running 911100-3: ✔ passed in 49.237535ms (RTT 67.964411ms) running 911100-4: ✔ passed in 194.935023ms (RTT 202.414171ms) running 911100-5: ✔ passed in 52.905305ms (RTT 66.254034ms) running 911100-6: ✔ passed in 52.597784ms (RTT 68.58854ms) running 911100-7: ✔ passed in 51.996881ms (RTT 67.496534ms) running 911100-8: ✔ passed in 50.804143ms (RTT 67.589557ms)👉 executing tests in file 913100.yaml
running 913100-1: ✔ passed in 276.383507ms (RTT 85.436758ms) running 913100-2: ✔ passed in 86.682684ms (RTT 69.89541ms) ...
If you want to run only one test, or a group of tests, you can specify that using the “include” option -i (or --include). This option takes a regular expression:
./go-ftw run --config .ftw.apache.yaml -d ../coreruleset/tests/regression/tests/ -i "955100-1$"
In the above case only the test case 955100-1 will be run.
If you need to see more verbose output (e.g., to look at the requests and responses sent and received by go-ftw) you can use the --debug or --trace options:
./go-ftw run --config .ftw.apache.yaml -d ../coreruleset/tests/regression/tests/ -i "955100-1$" --trace
./go-ftw run --config .ftw.apache.yaml -d ../coreruleset/tests/regression/tests/ -i "955100-1$" --debug
Please note again that libmodsecurity3 is not fully compatible with ModSecurity 2, some tests can fail. If you want to ignore them, you can put the tests into a list in your config:
testoverride:
input:
dest_addr: "127.0.0.1"port: 8080ignore:
# text comes from our friends at https://github.com/digitalwave/ftwrunner'941190-3$': 'known MSC bug - PR #2023 (Cookie without value)''941330-1$': 'know MSC bug - #2148 (double escape)'...
Also please don’t forget to roll back the modifications from this guide to your WAF configuration after you’re done testing!
Additional tips
⚠️ If your test is not matching, you can take a peek at the modsec_audit.log file, using: sudo tail -200 tests/logs/modsec2-apache/modsec_audit.log
🔧 If you need to write a test that cannot be written using text (e.g. binary content), we prefer using encoded_request in the test, using base64 encoding
Summary
Tests are a core functionality in our ruleset. So whenever you write a rule, try to add some positive and negative tests so we won’t have surprises in the future.
Happy testing! 🎉
Useful Tools
There are many first and third party tools that help with ModSecurity and CRS development. The most useful ones are listed here. Get in touch if you think something is missing.
A Coraza plus reverse proxy container for testing. Makes it possible to easily test CRS with Coraza in a similar way to testing CRS using the Apache and Nginx Docker containers.
A local CRS installation can be included using directives in a directives.conf file like so:
Include ../coreruleset/crs-setup.conf.example
Include ../coreruleset/rules/*.conf
An invaluable tool for testing how regular expressions behave and perform in both mod_security2 (the Apache module) and libModSecurity (ModSecurity v3).
Presents CRS rules using a structured UI, allowing for filtering and searching.
Syntax Highlighters
Regex Assembly
We have a syntax highlighting extension for Visual Studio Code that helps with writing assembly files. Instructions on how to install the extension can be found in the readme of the repository: https://github.com/coreruleset/regexp-assemble-syntax.
ModSecurity SecLang
A community member has created an experimental syntax highlighter extension for the ModSecurity SecLang for Visual Studio Code. It has a nice documentation feature for syntax elements and variables. Both highlighting and documentation have been generated using GPT-5, so expect some issues and inaccuracies. https://github.com/louis-lau/vscode-secrule-language-plugin.
Tools for Rule Writers
This page brings together essential tools that help rule writers create better, more effective CRS rules. From testing regular expressions to understanding database behavior, these resources will help you write rules using modern techniques and best practices.
Writing effective WAF rules requires understanding how attacks work, how payloads behave in different contexts, and how to create patterns that detect malicious behavior without causing false positives. The tools listed here will help you throughout the entire rule development process.
Regular Expression Testing and Development
Regular expressions are the foundation of many CRS rules. These tools help you write, test, and optimize regex patterns.
Essential for rule development. Provides real-time testing, detailed explanations of regex patterns, and performance analysis. Supports multiple regex flavors including PCRE (used by ModSecurity), Python, JavaScript, and Go. Features include:
A user-friendly regex testing tool with syntax highlighting and contextual help. Includes a searchable library of community patterns and supports PHP/PCRE and JavaScript regex flavors.
Provides visual regex debugging with railroad diagrams that show how patterns match. Particularly useful for understanding complex regex structures. Supports JavaScript, Python, and PCRE.
Online regex debugger supporting multiple languages including PHP (PCRE), Python, Ruby, JavaScript, Java, and MySQL. Features visualization of matches and helpful for testing regex across different platforms.
Database and Query Testing Playgrounds
Understanding how databases handle SQL queries, comments, spacing, and special characters is crucial for writing effective SQLi detection rules. These online playgrounds let you test query variations without local database setup.
Fast and easy-to-use online SQL playground supporting SQLite, MySQL, PostgreSQL, MS SQL Server, and more. Ideal for quickly testing how different databases handle query variations.
OneCompiler
Online compilers and playgrounds for multiple database systems:
Simple interface for running SQL queries against SQLite, MySQL, and PostgreSQL. Includes sample queries and makes it easy to share test cases with others.
Supports MySQL, PostgreSQL, and SQL Server with a clean interface for testing and learning SQL.
Encoding and Decoding Tools
Attack payloads often use various encoding schemes to evade detection. These tools help you understand how payloads can be transformed and ensure your rules handle encoded variants.
Quick URL encoding and decoding. Supports recursive decoding (up to 16 rounds) for payloads that are encoded multiple times. Essential for understanding URL-encoded attack payloads.
Real-time Base64 encoding/decoding with URL-safe encoding support. Useful for exploring how API credentials, JWT tokens, and other Base64-encoded payloads are structured. For security, use only anonymized or dummy data and never paste real secrets, such as live API keys or JWTs, into external online tools.
Multi-format encoding tool supporting ASCII to hex, Base32, ROT13, and more. Useful for testing various encoding transformations that attackers might use.
XSS and Security Payload Testing
Cross-site scripting (XSS) attacks use various techniques to bypass filters. These resources help you understand XSS vectors and test payload variations.
Comprehensive and regularly updated XSS payload reference. Contains vectors designed to bypass WAFs and filters. Essential resource for understanding current XSS techniques and testing rule effectiveness.
Modern, user-friendly command-line HTTP client. More intuitive than curl with JSON support, syntax highlighting, and better output formatting. Great for testing rule behavior with various HTTP requests.
Lightweight HTTP testing tool built on libcurl. Allows you to run and test HTTP requests with a simple plain-text format. Excellent for creating repeatable test scenarios.
CRS-Specific Development Tools
These tools are specifically designed for CRS development and are documented elsewhere in this guide.
crs-toolchain
The CRS developer’s toolbelt including the regexp assembler for building optimized regular expressions from data files. See crs-toolchain documentation.
go-ftw
Framework for Testing WAFs in Go. Essential for writing and running tests for your rules. See testing documentation.
Regexp Assembly Syntax Highlighter
Visual Studio Code extension for syntax highlighting of regexp assembly files. Makes it easier to write and maintain regexp data files. Available at github.com/coreruleset/regexp-assemble-syntax.
For a complete list of CRS development tools including testing frameworks, parsers, and Docker containers, see Useful Tools.
Rule Writing Workflow
Here’s a recommended workflow for developing new rules, incorporating many of the tools listed above:
1. Understand the Attack
Research the attack technique you want to detect
Collect real-world payload examples
Understand how the payload works in its target context
2. Test Payload Behavior
Use database playgrounds (SQLite Online, OneCompiler, etc.) to understand how databases process the payload
Test variations: spacing, comments, case sensitivity, encoding
Note which variations are functionally equivalent and must be detected
3. Develop Detection Pattern
Draft a regular expression to match the attack pattern
Use regex101.com to test and refine your pattern
Test against both malicious payloads and legitimate traffic
Optimize for performance (avoid catastrophic backtracking)
4. Consider Evasion Techniques
Test encoded versions using encoding/decoding tools
Consider how attackers might obfuscate the payload
Ensure your pattern handles common bypass techniques
5. Decide on Rule Placement
Determine if this is a new attack requiring a new rule
Or if it’s a variant that should be added to an existing rule
Preference: Extend existing rules when possible rather than creating new ones
6. Create or Update Rule
If extending an existing rule, update the regexp-assemble data file
Document Version: 1.0
Last Updated: 2026-02-19
Maintained by: OWASP CRS Team
1. Overview
The OWASP CRS Sandbox (https://sandbox.coreruleset.org/) is a public, shared testing environment that allows users to evaluate CRS detection capabilities against real payloads — without requiring a local WAF installation. Because it is publicly accessible and shared across all users, responsible usage is essential to ensure availability, integrity, and fair access for everyone.
This policy applies to all users of the CRS Sandbox, including security researchers, integrators, administrators, exploit developers, and CRS rule writers.
Validating new or modified CRS rules during development and review.
Research and publishing: generating detection evidence for vulnerability disclosures or security publications.
Integration testing: verifying CRS behavior across different backends and CRS versions.
3. Acceptable Use
Users may:
Send HTTP requests containing attack payloads representative of real-world exploits.
Use any HTTP method, header manipulation, or request body encoding to test detection.
Automate testing workflows within the rate limit specified in Section 5.
Use the X-Unique-Id response header to reference a specific request when reporting issues.
Select any available backend engine and CRS version for comparative testing.
Adjust paranoia level and anomaly score thresholds for evaluation purposes.
4. Prohibited Use
Users must not:
Use the sandbox as a proxy or relay to attack third-party systems.
Attempt to compromise the sandbox infrastructure itself (e.g., exploiting the OpenResty frontend, backend containers, or supporting services).
Deliberately trigger ReDoS (Regular Expression Denial of Service) conditions to degrade performance for other users. If a payload causes a timeout (HTTP 502), discontinue testing with that payload and report it as a potential ReDoS via a GitHub issue.
Send malformed HTTP requests that are designed to exploit the frontend server rather than the WAF/CRS layer. Requests rejected by the frontend with HTTP 400 are not processed by CRS and provide no valid test results.
Use the sandbox for sustained load testing or stress testing beyond the rate limits defined in Section 5.
Attempt to exfiltrate logs, audit data, or internal metadata from the sandbox infrastructure.
Use the sandbox for any activity that violates applicable local, national, or international laws.
5. Rate Limiting
To ensure fair access and availability for all users:
Do not send more than 10 requests per second.
Automated scripts and pipelines must implement appropriate throttling.
Excessive usage may result in temporary blocking of the originating IP address without prior notice.
The OWASP CRS Team will attempt to scale capacity in response to increased demand, but cannot guarantee availability under excessive load.
6. Data and Privacy
All requests sent to the sandbox are logged and processed by the sandbox infrastructure.
Logs are written to an S3 bucket and an Elasticsearch cluster, and reviewed via Kibana by the OWASP CRS Team.
Do not send real personal data, credentials, API keys, or any sensitive information in your requests.
User-Agent strings and geolocation data are extracted from logs for operational analytics.
By using the sandbox, you acknowledge that submitted request content may be retained and analyzed by the OWASP CRS Team for the purpose of improving CRS rules and sandbox infrastructure.
7. Responsible Disclosure
If you discover a vulnerability in the sandbox infrastructure itself, please do not attempt to exploit it and do not disclose it publicly. Instead, send a private email to security@coreruleset.org with:
A clear description of the vulnerability and its potential impact.
Steps to reproduce, including any relevant request details.
The X-Unique-Id response header value from your request, if available.
Please allow reasonable time for the team to assess and remediate before any public disclosure.
The OWASP CRS Team will respond as quickly as possible.
8. Known Limitations
Users should be aware of the following sandbox behaviors to avoid misinterpreting results:
Issue
Cause
Symptom
Malformed HTTP requests not scanned by CRS
OpenResty or backend server rejects the request before CRS processes it
HTTP 400 response
ReDoS causing request failure
A payload triggers catastrophic backtracking in a regex
HTTP 502 after long delay
Default backend/version
Requests without X- headers use Apache 2 + ModSecurity 2.9 and the latest CRS release
Unexpected detection results when comparing engines
Detection-only mode
When x-crs-mode: detection is set, the WAF does not block; this affects score threshold behavior
No blocking even above threshold
9. Sandbox Detection Output Is Not a Vulnerability Report
The CRS Sandbox is intentionally designed to detect attacks and report matched rules. Its output — including rule IDs, anomaly scores, and matched patterns — is publicly documented and expected behavior, not evidence of a vulnerability.
We periodically receive reports claiming a vulnerability was found in the sandbox, accompanied by txt-matched-rules output showing that a payload was detected. To be unambiguous: a payload being detected by the sandbox is the sandbox working correctly. This is not a security finding.
A valid security report for the CRS Sandbox would involve one of the following:
A payload that bypasses CRS detection when it should be caught (a false negative in a specific CRS version or engine).
A vulnerability in the sandbox infrastructure itself (e.g., a flaw in the OpenResty frontend, backend containers, or supporting services).
A ReDoS condition triggered by a specific payload that causes backend instability.
Reports that consist solely of sandbox detection output, WAF audit logs, or anomaly scores generated through normal sandbox usage will be closed without further response.
10. No Bug Bounty Program
The OWASP CRS project is a volunteer-driven, open-source initiative. We do not operate a bug bounty program and we do not offer monetary rewards of any kind for vulnerability reports, security research, or any other contributions.
If you submit a report and receive a thank-you from the team, please understand that this is an acknowledgment of your effort and nothing more — it does not imply eligibility for compensation.
We are grateful for genuine contributions to CRS security, and we recognize meaningful work through community credit, changelog attribution, and public acknowledgment where appropriate.
11. Questions, Feedback, and Support
For questions, bugs, or feature suggestions related to the CRS Sandbox:
Open a GitHub issue: https://github.com/coreruleset/coreruleset/issues
Tag the issue appropriately (e.g., sandbox, bug, enhancement).
The OWASP CRS Team reviews issues regularly and will respond as resources allow.
12. Policy Updates
This policy may be updated at any time. Significant changes will be announced via the OWASP CRS GitHub repository. Continued use of the sandbox constitutes acceptance of the current policy.
This policy is maintained by the OWASP CRS Team. The CRS Sandbox is a community resource — please use it responsibly.
Known Issues
There are some known issues with CRS and some of its compatible WAF engines. This page describes these issues. Get in touch if you think something is missing.
Warning
There are still false positives for standard web applications in the default install (paranoia level 1). Please report these on GitHub if and when encountered.
👉 False positives from paranoia level 2 and higher are considered to be less interesting, as it is expected that users will write exclusion rules for their alerts in the higher paranoia levels. Nevertheless, false positives from higher paranoia levels can still be reported and the CRS project will try to find a generic solution for them.
AH00111: Config variable ${…} is not defined
Apache may give an error on startup when the CRS is loaded:
AH00111: Config variable ${[^} is not defined
It appears that Apache tries to be smart by trying to evaluate a config variable. This notice should be a warning and can be safely ignored. The problem has been investigated and a solution has not been found yet.
ModSecurity 3.0.0-3.0.2 will give an error
Expecting an action, got: ctl:requestBodyProcessor=URLENCODED"`
Support for the URLENCODED body processor was only added in ModSecurity 3.0.3. To resolve this, upgrade to ModSecurity 3.0.3 or higher.
Old Debian versions without YAJL
Debian releases up to and including Jessie lack YAJL/JSON support in ModSecurity. This causes the following error in the Apache ErrorLog or SecAuditLog:
ModSecurity: JSON support was not enabled.
JSON support was enabled in Debian’s package version 2.8.0-4 (Nov 2014). To resolve this, it is possible to either use backports.debian.org to install the latest ModSecurity
release or to disable the rule with ID 200001.
Apache 2.4 prior to 2.4.11
Apache versions prior to 2.4.11 are affected by a bug in parsing multi-line configuration directives, which causes Apache to fail during startup with an error such as:
By now you should not be using such an old web server. It is advisable to upgrade your Apache version. If upgrading is not possible, the CRS project provides a script in the util/join-multiline-rules directory which converts the rules into a format that works around the bug. This script must be re-run whenever the CRS rules are modified or updated.
Support for application/soap+xml
As of CRS version 3.0.1, support has been added for the application/soap+xml MIME type by default, as specified in RFC 3902. OF IMPORTANCE: application/soap+xml is indicative that XML will be provided. In accordance with this, ModSecurity’s XML request body processor should also be configured to support this MIME type. Within the ModSecurity project, commit 5e4e2af has been merged to support this endeavor. However, if running a modified or preexisting version of the modsecurity.conf file provided by this repository, it is a good idea to upgrade rule ‘200000’ accordingly. The rule now appears as follows:
SecDisableBackendCompression not supported in libmodsecurity3
All versions of libmodsecurity3 do not support the SecDisableBackendCompression directive at all.
If Nginx is acting as a proxy and the backend supports any type of compression, if the client sends an Accept-Encoding: gzip,deflate,... or TE header, the backend will return the response in a compressed format. Because of this, the engine cannot verify the response. As a workaround, you need to override the Accept-Encoding and TE headers in the proxy:
server {
server_namefoo.com;
...location/ {
proxy_passhttp://backend;
...proxy_set_headerAccept-Encoding"";
proxy_set_headerTE"";
}
}
Webserver returns error after CRS install
This is likley due to a rule triggering. For instance in some cases a rule is enabled that prohibits access via an IP address. Depending on your SecDefaultAction and SecRuleEngine configurations, this may result in a redirect loop or a status code. If this is the problem you are experiencing you should consult your error.log (or event viewer for IIS). From this location you candetermine the offending rule and add an exception if neccessary see false positives and tuning.
Additional Resources
Note
The content on this page may be outdated. We are currently in the process of rewriting all of our documentation: please bear with us while we update our older content.
Free and Open-Source Community Help
CRS GitHub repository. Open issues for bugs, report false positives, and access the source code.
There is an extended set of tutorials at netnea.com, that introduces the CRS integration and the handling of false positives with great detail. It is worth checking out:
ModSecurity Handbook is “The definitive guide to the popular open source web application firewall”, by Christian Folini and Ivan Ristić. The book is available from Feisty Duck in hard copy or with immediate access to the digital version which is continually updated.
Web Application Defender’s Cookbook: Battling Hackers and Defending Users
ModSecurity 2.5 is “A complete guide to using ModSecurity”, written by Magnus Mischel. The book is available from Packt Publishing in both hard copy and digital forms.*
Apache Security
Apache Security is a comprehensive Apache Security resource, written by Ivan Ristic for O’Reilly. Two chapters (Apache Installation and Configuration and PHP) are available as free download, as are the Apache security tools created for the book.
Preventing Web Attacks with Apache
Preventing Web Attacks with Apache. Building on his groundbreaking SANS presentations on Apache security, Ryan C. Barnett reveals why your Web servers represent such a compelling target, how significant exploits are performed, and how they can be defended against.